「A Survey of Model Compression and Acceleration for Deep Neural Networks」の7,8章だ。一応今回で謝辞を除く全ての章を訳すことができたので、これでこの論文は終りとなる。
ここ最近は読みたい本が多すぎて悶々としていたが、目移りせず無事に最後まで訳せて良かった(;^ω^)
A Survey of Model Compression and Acceleration for Deep Neural Networks
Benchmarks, Evaluation and Datasets
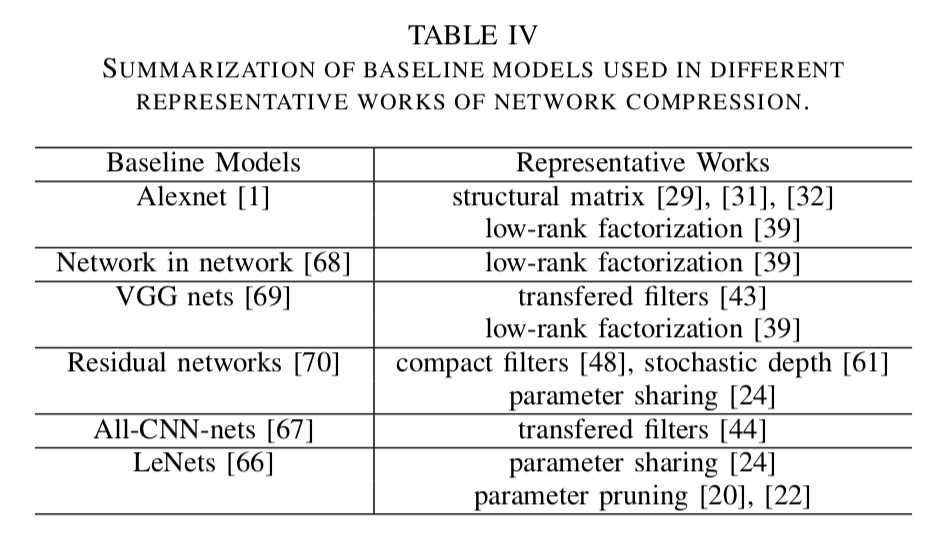
過去5年の間、ディープラーニングコミュニティはベンチマークモデルに対して多大な努力を図ってきた。CNNの圧縮と高速化に利用されている最もよく知られているモデルの1つはAlexnetである。これはよく圧縮の性能を見積もる際に利用される。他の有名な標準的モデルには、LeNetsやAll-CNN-nets等がある。LeNet-300-100は全結合のネットワークであり、300と100の2つの隠れ層を有している。LeNet-5は、2つの畳み込み層と2つの全結合層を持つ畳み込みネットワークである。
近年、多くの研究で更にたくさんのSOTAなアーキテクチャがベースラインモデルとして用いられている。これはnetwork in network(NIN)うやVGGネット、residual networks(ResNet)などを含む。テーブルⅣは典型的な圧縮手法において、よく用いられているベースラインモデルのサマリである。
モデル圧縮と高速化の質を測るための標準的な基準は、その圧縮率と加速率を測定することである。元のモデルのパラメータの数を、圧縮後のモデルのパラメータ数をとすると、その圧縮率 は以下で表される。
その他の広く使われている測定法は、研究1, 2において、以下の用に定義さたインデックス空間の節約である。
とはそれぞれ、元のモデルと圧縮後モデルにおけるインデックス空間の次元数である。似たように、の実行時間と、の実行時間が与えられた時、その高速化率 は以下のように定義される。
実行時間を測定するために、多くの研究がエポックごとのトレーニング時間の平均を用いている一方で、研究1, 2(https://arxiv.org/abs/1502.03436)ではテスト時間の平均を用いている。小さなモデルがトレーニングとテストのステージでより高速に計算されるように、一般的に圧縮率と高速化率には強い相関関係がある。
良い圧縮法は、同じモデルであっても、より少ないパラメータと計算時間で元のモデルとほとんど同じ性能を達成することが期待できる。しかしながら、異なるCNNデザインを有する異なるアプリケーションでは、その性能や計算時間に於ける関係もまた違ってくるだろう。例えば、全結合層を含む深いCNNに於いて、その殆どのパラメータは全結合層内にあること観測されている。一方でイメージ分類タスクにおいては、その主な浮動小数点演算は初めの少数の畳み込み層である。これは、初めの方では画像のサイズが非常に大きく、各フィルタはその画像全体に対して畳み込まれるためである。従って、ネットワークの圧縮と高速化は、異なるアプリケーションのための異なるタイプの層に焦点を当てるべきである。
ネットワークの圧縮や高速化の効用を測定する際に、よく用いられる3種類の方法が紹介されている。
普段も似たような感じで測定してたけど、きちんとまとめられているのは嬉しい。(^ν^)
また、それらが導入された研究も分かってよかった。
Discussion and Challenges
本論文は、近年のディープニューラルネットワークの圧縮と高速化におけるまとめを行っている。ここでは、如何にして異なる圧縮アプローチを選択すれば良いのか及び、可能な挑戦とその解決策についての詳細を議論する。
A. General Suggestion
4つの手法の内で、どの手法が一番優れているのかを測定するゴールデンルールは存在しない。如何に適切なアプローチを選択するかは、本当にそのアプリケーションと要求に依存する。我々が提案可能ないくつかの汎用的な提案をここで紹介する。
-
もし、アプリケーションにプレトレインモデルを元にしたコンパクトなモデルが必要であるならば、pruning & sharingまたはlow rank factorizationをベースとする手法を選択することができる。また、その問題にエンドツーエンドな解決策が必要な場合、low rank factorizationとtransferred convolutional filterアプローチが良い。
-
幾つかの特定の領域のアプリケーションに対しては、transferred convolutional filtersやstructural matrixのような人間の事前知識から恩恵が受けられることが多い。例えば医療画像の分類においては、臓器のような医療画像が回転変形特性を有するため、transferred convolutional filtersは上手くいくはずである。
-
pruning & sharingのアプローチは、精度を悪化させずに理にかなった圧縮率を提供できるだろう。従って、安定的なモデル誤差が必要なアプリケーションにおいては、pruning & sharingを活用するのが良い。
-
もしその問題が小さいまたは中間的なサイズのデータセットに関連しているのであれば、knowledge distillationアプローチを試してみるべきである。圧縮された生徒モデルは、教師モデルからの知識の移転の恩恵を受けることができ、大きくなくとも堅牢なデータセットになる。
-
セッション1でも述べたように、4つのテーマのテクニックは直行している。圧縮率や高速化率を最大化するために、それらの2つまたは3つを組み合わせることは理にかなっている。畳み込み層と全結合層の双方を必要とする物体検知のような幾つかの特定のアプリケーションに対しては、畳み込み層をlow rank factorizationで、全結合層をpruning手法で圧縮することができる。
Technique Challenges
深いモデルの圧縮と高速化の技術はまだ早期の段階であり、今後取り組まれるべき挑戦を以下に述べる。
-
現在のSOTAなアプローチの殆どがよく設計されたCNNモデルの上に構築されているが、それらは設定変更の自由度に制限がある。より複雑なタスクを行うためには、圧縮されたモデルの構成を提供するためのより妥当な方法が必要である。
-
プルーニングはCNNの圧縮と高速化を行うのに効率的な方法である。現在のプルーニング技術は、主にニューロン間の結合を取り除くようにデザインされている。一方で、チャーネルをプルーニングすることは特徴マップの幅を直接減らし、そのモデルをより薄いものに縮小する。これは効率が良いが、チャネルの削除が続く層の入力を劇的に変えるため挑戦的である。この問題に対処する方法を説明することは重要である。
-
前に述べたように、structural matrixとtransferred convolutional filtersの手法は、事前知識をモデルに強要するため、その安定性や性能に多大な影響を与える可能性がある。どのように課せられた事前知識の影響度合いを操作するかを調査することはことは極めて重要である。
-
knowledge distillationの手法は、専用ハードウェアや実装を必要としない直接の高速化のなどの多くの利点を提供する。KDベースのアプローチを実装することや、その性能を改善する方法を探索することは未だに価値がある。
-
様々な小型プラットフォーム(例えば、モバイル、ロボット、自動運転車)におけるハードウェアの制約は、依然として深いCNNの拡張を妨げる主要な問題である。いかにして利用可能な限られた計算資源を最大限に活用するか及び、どのようにそれらのプラットフォームに対する特別な圧縮手法を設計するかは、依然として取り組まれるべき挑戦である。
Possible Solutions
ハイパーパラメータの設定の問題を解決するために、我々は近年のlearning-to-learn戦略に頼ることができる(1, 2)。このフレームワークは”どのように関心のある問題の構造を活用するか”をアルゴリズムに自動的に学習させるメカニズムを提供する。ここには、learning-to-learnモジュールをモデルの圧縮と組み合わせるための2つの異なる方法がある。一つ目は圧縮とlearning-to-learを同時に設計する。一方で、二つ目は初めにlearning-to-learnを用いてモデルの構築を行い、その後パラーメタをプルーニングする。
チャネルプルーニングは特別な実装が不要なため、CPUとGPUの両方に効率的なメリットをもたらします。しかし、入力設定を処理することが難しいという問題があります。この可能な解決策の1つは、訓練時にスパース制約を重みに課することで訓練ベースでチャネルプルーニングをを行う方法である(Jose M Alvarezら)。これは、適応的にハイパーパラメータを特定する事ができる。しかしながら、このような手法のためのスクラッチからのトレーニングは非常に深いCNNにおいてコストである。Yihui Heらは各層のチャネルを効果的にプルーニングするための反復的な2ステップアルゴリズムを提供した。
教師モデルにおける新しいタイプの知識を探求し、それを生徒モデルに転移することは、KDのアプローチにとって有益である。教師モデルから直接パラメータを削減及び転移する代わりに、選択的にニューロンの知識を渡すほうが役に立つ可能性がある。これは、タスクに関連した本質的なニューロンを選択するための方法を求める1つの方法である。その直感は、ニューロンがある特定の領域やサンプルにおいて活性化されている場合、それらの領域やサンプルがタスクに関連する可能性のある共通の特性を共有していることを意味する。このようなステップを踏むことは時間を消費するため、効率的な実装は重要である。畳み込みフィルタや構造行列を用いた手法において、その変換は空間次元内でのみ動作する関数のファミリ内に存在すると結論付けることができる。従って、課された先の問題に取り組むための1つの解決策は、以下の2つの側面において上で述べたアプローチの一般化を提供することである。
-
変形を所定の変形のセットに属するものに限定する代わりに、二次元のフィルタまたは行列に適用された空間的変形のファミリ全体であるとする
-
全てのモデルパラメータと共にその変換を学習する
小さなプラットフォームにおけるCNNの使用に関して、いくつかの汎用かつ統一的なアプローチを提案することは1つの方向性である。Yuhenらは元のモデルの本質的な情報を保持する可能性のある異なるフィルタによって生成された特徴マップ内にある冗長性を発見または削除する手法により、特徴マップを次元的に削減する手法を提案した。このアイディアはCNNを異なるアプリケーションに対してより適用しやすく拡張することができる。Yong-Deok Kimらの研究では、深いCNNをモバイルデバイス上で動作させるために、ランク選択、低ランクテンソル分解、ファインチューニングの3つの構成部品から成るワンショットでネットワーク全体を圧縮する方式を提案した。システム的な側面からは、FacebookがよりプラットフォームであるCaffe2をリリースした。これはとりわけ軽量かつモジュール化されたフレームワークを採用しており、ハードウェア設計に基づいたモバイル固有の最適化を含んでいる。Caffe2は、開発者や研究者が大規模な機械学習モデルを訓練することやAIをモバイルデバイスに提供するのに役立つ。
全体を通して、半分くらいは知らない内容だった。(;^ω^)
ただ、本当に概要だけだけれど、この領域に関する全体的な分類や流れ、歴史を俯瞰できたのは嬉しい。
「少し木を見てから森を見る、最後にその葉まで見る」
自分の何かを学ぶ時のモットーとしている言葉だ。
今回で森を見ることができたかな??(^ω^)
今後は各領域について細かくまとめていければいいかなと考えている。
コメント
コメントを投稿