最近、仕事の忙しさにかまけて全然ブログを更新できていなかったが、なんとかGPUを支える技術の5章までを投稿することができた。
時間がないわけではないのだけどだけど、普通の読書や実装などに時間を割くと、なかなか文章を書く暇がない。。 _| ̄|○
効率を重視しながらも、重要なところを上手くまとめて復習に役立てられるブログにしていきたい。
第5章 GPUプログラミングの基本[前半]
5.4 GPU プログラムの最適化
GPUで最大限力を発揮するには、その資源を有効に使うプログラム作成する必要がある。
具体的には以下のような点が重要である。
-
スレッドブロックはSMの数の整数倍にする
NVIDIAのGPUはスレッドブロック単位で各SMに割り当てられ計算される。1度の割当で計算しきれない分は2巡目以降にで割り当てられる。この場合、スレッドブロックの数が中途半端だと最後のターンでSMにあまりが出てしまう。ただし、複数カーネルを同時に実行する機能もあるので、他のカーネルがあれば空いたスペースは自動で埋められる。
-
演算機の計算パイプラインを意識する
演算器が前の計算を行ってからその結果を再度利用するには10サイクルほど要する。NVIDIA GPUはワープ(32スレッド)を同時に計算を行うが、ワープの結果を利用する予定の他のワープはその実行時間分を待つ必要がある。この隙間時間はワープスケジューラが別のワープを演算機に割り当てるが、全部で64ワープしかない、SM1つあたりのレジスタファイルは65,536個(1スレッドあたり32個)しかないということを考慮してプログラムを作成する必要がある。なお、ワープがDDRアクセスを必要とする場合、400〜800サイクルかかることもある。
-
条件分岐への配慮
以前の章でも説明したとおり、プレディケートによる条件分岐はif, elseの両方を実行するので、分岐実行されるプログラムはなるべく短くなるほうが良い。
-
メモリアクセスと演算の比率
以前の章で既出。現状のコンピュータでは演算速度よりメモリ帯域によってその速度が制限される。スパーコンピュータ京で約$0.5Byte/Flop$、NVIDIA P100では$0.136Bype/Flop$となる。なおこの逆数$Flops/Byte$のことを算術強度と呼び、単純な演算機性能であるFlops を縦軸、算術強度を横軸にとった時、その上限値はある地点まではメモリ帯域によって決まる。その見た目からをルーフラインモデルと呼ばれる。ルーフラインモデルは余り精度は無いが、容易に性能を見積もることができるので、よく利用される。(Qiitaの記事より、以下に画像を引用)
- メモリアクセスパターン
4章のロード/ストア命令の部分で触れた。一度のロード/ストアデータの幅は128byteであるため、スレッドが要求したアドレスがこの領域内になければリプレイが必要となる。NVIDIAのであれば1つのワープは32スレッドを含むため、最悪の場合は32倍のロード/ストア時間がかかる。従って、各スレッドがなるべく近い位置にあるデータを利用するように心がける必要がある。
アルゴリズム的にその計算に必要なデータを近い位置に置けない場合はシェアードメモリを使うという手がある。シェアードメモリはデバイスメモリに比べて100ほど速い(L2キャッシュヒット時は10倍)ので、どうしてもリプレイが多くなってしまうような場合に効果がある。
NVIDIA GPUのシェアードメモリは32このバンクで構成されている。この構成を用いて、行列積などの列方向への連続アクセスが必要なアルゴリズムによく利用される実装として、行方向の要素の後に余分なダミー要素を1つ入れるという手法がある。こうすると、各行の対応する要素が異なるバンクに割り当てられるので行方向の要素を一度で取得することができる。
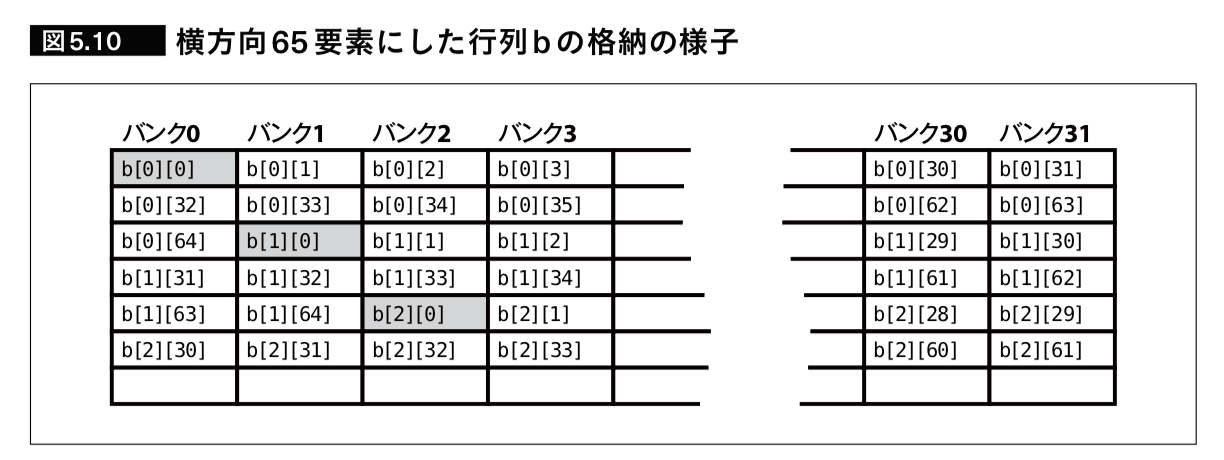
出展: 「GPUを支える技術」,p212,Hisa Ando,2017
データのサイズが大きく、キャッシュやシェアードメモリ等の高速メモリに載り切らない時に有効な方法にブロッキングがある。例えば行列積$C_{i,j} = \sum{A_{i,k} \cdot B_{k,j}}$でシーケンシャルアクセスが必要となる方向に対して、その範囲を区切り一部のみをメモリに載せることでメインメモリ(デバイスメモリ)へのアクセスを減らすことができる。なお、ブロッキングはレジスタで行うことも可能。
- 通信と計算のオーバラップ
GPUを用いる計算では一般的に、CPUメモリからGPUメモリにデータをコピーし、計算が終わってから再度書き直しを行う。このため、GPUは一般的にDMAエンジンを演算器とは別に持っており、それぞれが独立に動作する(中にはリードとライトの2つのDMAを持つものもある)。GPUを効率的に利用するには上記のDMAをうまく使い、演算同時にと次の計算に必要なデータをロードしておくダブルバッファの手法がよく用いられる。ただし、このためには現在演算中のデータとは別にメモリスペースを確保する必要がある。また、プログラムはより本雑になり、コードが読みにくくなるという欠点もある。
5.5 OpenMPとOpenACC
これまでで説明したGPUプログラミンはある程度抽象化されていると言っても、やはり敷居は高い。従って、これらをC言語にディレクティブを加えるだけで利用可能にしようという試みがOpenACCやOpenMPである。
OpenMPは1997年に、複数CPUのシステムが共有のメモリを利用するSMP(Symmetric Multi-Processor)システムを前提として、それぞれのCPUに対するループの分担を自動化するために作成された。その後、これをCPUとGPUのようなヘテロジニアスな環境でも利用できるようにディレクティブによる拡張を試みたが、GPUの他にGDSPやSIMDもサポートしたため仕様の策定が遅延した。その結果、別の主張を方針としたOpenACCが分岐し、2012年にリリースされた。
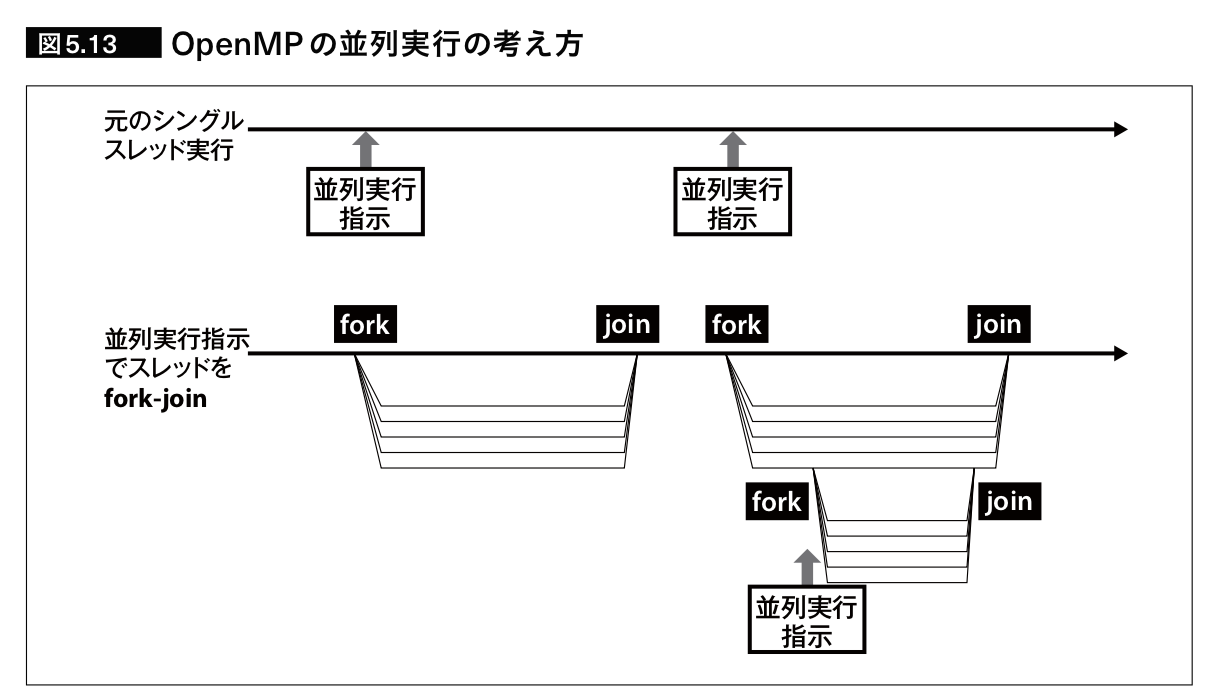
出展: 「GPUを支える技術」,p213,Hisa Ando,2017
OpenACC
OpenACCはホストCPUに1台のアクセラレータが接続された環境を想定している。OpenACCではfor文の前に#pragma acc parallel forの指示子を挿入すると、小スレッドをGPUを立ち上げて実行する。この際に、そのメモリ領域の確保やデータ転送もコンパイラが代わりに担当する。
OpenACCは以下3つの並列形式を持つ(NVIDIA GPUにおける並列レベルの対応も同時に記載)。
- gang並列: スレッドブロックレベル
- worker並列: ワープレベル
- vector並列: SIMDレベル
これは非常に簡単に利用することができる。以下にベクトルの要素毎の和のプログラムを例に示す。
void VecAdd(int n, float* a, float* b, float* c)
{
#pragma acc kernels
for (int i = 0; i < n; ++i)
c[i] = a[i] + b[i]
}
出展: 「GPUを支える技術」,p220,Hisa Ando,2017
上記のコードをコンパイルすると、pragmaの下のforループ文をGPUで実行するプログラムが作成される。たった一行でGPUを使って並列に計算するプログラムができるので非常に便利であるが、幾つか欠点もある。まず、1つのイテレーションの中に前にデータ依存関係がある場合、それを解決できない(例: c[i]=a[i]+b[i]+c[i-1])。他にも、ループの開始時点でその実行回数がわからない場合、、スレッド分割できないので並列化ができない。また、ディープコピーに対応していないという問題もある。
上記のコードでは変数のa,b,cその領域がカーネル実行前にデバイスメモリにコピーされ、実行後に再度デバイスメモリに上書きされる。しかし、実際にはcは初めにデバイスメモリにコピーする必要はなく、同時にa,bもホストメモリに書き戻す必要はない。
OpenACCでは各ループが別々のカーネルになる。その際、各カーネルにおいて共通して利用されるデータが毎回メモリにコピーされることを防ぐ指示子も用意されてる。#pragma acc kernels copyin(a,b) copyout(c)をforループ前に書くと、上記で無駄な転送を行わなくて済む。また、上記のループを含むカーネル処理が終了しても、再度次のカーネルでcを使いまわしたい場合は、#pragma acc dataを指定する。
OpenMP
OpenMpはシングルスレッドプログラムを元にし、並列実行できる部分をディレクティブにより、コンパイラに教えることができる。各CPUはその情報を元、スレッドを作成して処理を分担する。この点はOpenACCも基本的には同じであるが、OpenMPは1台のCPUに同一のデバイスを数台接続する構成がサポートされている。以下にOpenACCで用いたコードをOpenMPを使って記述したものを以下に示す。
#pragma omp target map(to: n, a[0:n], b[0:n]) map(from: c[0:n])
{
int i;
#pragma omp parallel for
for(i = 0; i < n; ++i)
c[i] = a[i] + b[i];
}
出展: 「GPUを支える技術」,p223,Hisa Ando,2017
OpenMPの場合、#pragma omp targetの次の文がデバイスで実行されるカーネルであることを示す。また、その後に続くmap(to: ...)やmap(from: ..)はOpenACCの場合と同様にホストメモリへのコピーをコントロールするための指示である。
また、OpenMPにも複数のカーネルにまたがってデータを保持するための機能があり、#pragma omp target dataで指定されたデータは次の行または{}のスコープで囲まれた範囲で存在し続ける。OpenMP4におけるスレッドの群はteamで表し、それらの集合であるleagueという単位も存在する。各teamの数やteam内のスレッド数を制御するためのnum_temasやthead_limitもある。これらは定義または処理を分散するために利用される。
OpenACCとOpenMP4は指示子の追加のみでスレッド並列やスレッドブロック並列等の並列化レベル指定ができるが、OpenMP4の利点として、SMPのマルチプロセッサや複数台GPU、DSPなどのアクセラレータもサポート点が挙げられる。しかし、逆にコンパイラ開発には手間がかかるため、各デバイスのコンパイラにおいてサポート状況が異なる問題もある。
まとめ
GPUによる科学技術計算は約10年ほどの歴史しかないが、スーパーコンピュータの性能ランキングであるTop500でも、多くのシステムがGPUを利用している。この急速な普及の背景にはCUDAやOpenCLなどのC言語拡張の貢献がある。
GPUの性能を引き出すためには、そのアーキテクチャを活かしたプログラムを記述しなければならない。大きなボトルネックの原因として演算能力と比較してメモリ帯域という点があるため、複数の内部メモリをどのように活用すれば効率的なプログラムが作成できるかについてについて述べた。
上記のC言語拡張の言語を用いたプログラムは、メモリ確保やデータ転送の命令などを多く含むため複雑になりやすい。従って、既存のCプログラムに指示子を導入するだけで、デバイス上でのカーネル実行や分散メモリの領域確保、メモリ間コピーまで行うことができるOpenACCとOpenMPについても紹介した。
コメント
コメントを投稿