今回は2/17日にドワンゴさんで行われたFPGAXでの発表で紹介したサーベイ論文「A Survey of FPGA Based Neural Network Accelerator」の邦訳を掲載することにする。
稚拙ながら発表スライドも以下にあるので興味のある方はぜひ御覧ください。( ´∀`)
https://www.slideshare.net/leapmind/an-introduction-of-dnn-compression-technology-and-hardware-acceleration-on-fpga-88557866
A Survey of FPGA Based Neural Network Accelerator
Kaiyuan Guo, Shulin Zeng, Jincheng Yu, Yu Wang, Huazhong Yang
https://arxiv.org/abs/1712.08934
Abstruct
ニューラルネットは画像やスピーチ、ビデオ認識などの領域に適用され、良い結果を残している。しかし、その計算のストレージや複雑度が、アプリケーションでの活用を難しくしている。CPUでの計算は難しいため、GPUが最初の選択肢となる。
一方で、FPGAを基にしたアクセラレータも研究の対象となってきている。なぜなら、特化したハードウェアの設計はGPUを速度とエネルギー効率で超えるための、有力な選択肢であるためである。様々なFPGAベースのアクセラレータがソフトウェアとハードウェアの最適化手法を用いて提案されてきている。本稿では、それらの全体図とそれらの主要な技術の要約を行う。この調査はFPGAベースのNNアクセラレータについて、そのソフトウェア側からハードウェア側、回路レベルからシステムレベルに渡り、包括的な分析を行い、未来の研究への展望をて供する。
1. Introduction
近年のNNの研究では伝統的なアルゴリズムの素晴らしい改善が見られている。それらには画像、ビデオ、音声処理におけるCNNやRNNなどがある。CNNはImageNetにおけるTop5の画像分類精度を73.8%から84.7%に引き上げ、物体認識にも貢献した。RNNはSOTAな語誤差をスピーチ認識で達成した。
しかし、その計算やストレージの複雑度は高い。現在の研究によると、NNのモデルサイズは未だに増加し続けている。CNNの例によると、最も大きいCNNは224 x 224の画像サイズで390億の浮動小数点数演算を必要とし、500MB(VGG[1])のモデルパラメータを持つ。計算複雑度は入力のサイズに比例するため、高解像度の画像を計算するには1000億以上の演算が必要になるだろう。
従って、NNを基としたアプリケーションの計算プラットフォームを選択することは重要である。一般的なCPUは10-100G FLOPを1秒間に実行する。その電力効率は多くの場合1GOP/Jを下回る。CPUは高性能が求められるクラウド上のアプリケーションや低消費電力要求のあるモバイルアプリケーションに適用することは難しい。CaffeやTensorflow等の開発フレームワークはGPUは初めの選択肢として、NNの高速化に用いる。
CPUやGPUの一方で, FPGAがエネルギー効率の良いNN計算のプラットフォームの候補になりつつある。NN指向のHWデザインにおいて、FPGAは高い並列性や不必要なロジックを排除することででNNの計算特性を活用することができる。アルゴリズムの研究においても、その精度を低下させることなく、NNモデルをHWフレンドリな方法に単純化することができることが示されている。これはFPGAがCPUやGPUと比較して高いエネルギ効率を達成するを可能にしている。
FPGAを基にしたアクセラレータの設計は、その性能と柔軟性において2つの挑戦に直面している。
- 現在のFPGAは一般的に100-300MHzの周波数で動作しており、これはCPUやGPUよりかなり低い。また、FPGAのロジックには再構成のオーバーヘッドがあり、これはシステムの全体的な性能を低下させる。単純な設計の転用により高性能、高エネルギー効率を達成することは難しい。
- FPGA上におけるNNの実装はCPUとGPUを用いる場合よりかなり難しい。CPUやGPUにおけるCaffeやTensorflowのような開発フレームワークがFPGAにも必要である。
上記2つの問題に対して、多くの研究者がエネルギー効率が高く、柔軟なFPGAベースのNNアクセラレータを実装してきている。本稿ではこれらの研究により提案された技術を以下の観点から要約する。
- 初めに、エネルギーベースの設計における方法論を分析するため、FPGAベースのNNアクセラレータの性能に関する簡単なモデルを紹介する
- 高性能とエネルギー効率のよりNNアクセラレータの設計について、現在の技術を調査する
- 最先端のNNアクセラレータ設計を比較することで導入された技術を評価し、現在のGPUより少なくとも40倍優れたFPGAベースのアクセラレータ設計の達成可能な性能を評価する。
- 最先端のFPGAベースのNNアクセラレータ向け設計メソッドの調査をする。
本稿の残りの部分は以下のように構成されている。
- Section 2: NNに於ける基本的演算の紹介する
- Section 4 & 5: ソフトウェアとハードウェアそれぞれにおけるNNアクセラレータ技術のレビュー
- Section 6: 既存設計の比較と、技術の評価
- Section 7: 柔軟性のあるアクセラレータ設計手法の紹介
- Section 8: 本稿の結論
### 2 Preliminary on Neural Network
このセクションではNNアルゴリズムにおける基本的な演算を紹介する。
Fully connected layer (FC)
全ての入力ニューロンと出力ニューロンを重みを用いて結合することで実装する。バイアス後を加えると以下のようになる。
Convolution layer
この層は二次元ニューロンの計算を行う。これは一般的に画像処理向けのCNNの採用されている。入力と出力のニューロンは2次元特徴マップ$F_{in}$と$F_{out}$のセットと見なすことができ、それぞれの特徴マップはチャンネルと呼ばれる。ここで、2次元の畳込みカーネルとバイアス$b_i$を加えると出力の要素$F_{out}(j)$は以下のように表される。
二次元の畳み込みには様々な種類が存在する。最も一般的なのはパディングを用いたカーネルサイズ3x3のものである。また、計算量や特徴マップのサイズを削減する目的で、より大きい5x5や7x7でストライドが1より大きい値を用いることも一般的である。また、比較的最近の手法として1x1のカーネルサイズを用いるものも出てきた。
Non-linear layer
初期にはシグモイド関数やハイパボリックタンジェントがよく用いられており、現在でも音響または音声認のRNNで利用されている。多くの最先端モデルに用いられておりReLUは生のニューロンを保ちながら、負のニューロンを0としてフィルタするものである。近年でPReLUやLeaky ReLUのような様々なReLUが用いられてる。
Pooling layer
Max poolingとAverage poolingの2つがよく用いられる。Average Poolingは特徴マップを小さなウィンドウに分割してその平均値を各ウィンドウ毎に求めるのに対し、Max poolingは最大値を求める。一般的なウィンドウサイズは2x2(ストライド 2)または3x3 (ストライド 3)である。
Element-wise layer
2つの等しいサイズのベクトルを入力とし、それぞれ対応した要素毎に指定された演算を適用する。ResNetではelement-wise addition、RNNはelement-wise subtractionまたはmultiplicationが求められる。
## 3. Design Methodology
高速化とエネルギー効率の向上を目的としたNNアクセラレータの各技術の詳細に立ち入る前に、その設計方法論の全体像を示す。一般的に、NN演算システムは3つの側面である高いモデル精度と高いスループット、高いエネルギー効率を含んでいる。また、ある種のアプリケーションに対しては高い柔軟性もまた検討する必要がある。
一般的に巨大なNNモデルは高い精度を持つ。ResNetやAlexnet、VGGなどのような異なるネットワーク構造はその精度に影響するが、本稿の範疇ではない。同様のモデルに対して圧縮手法を適用することはスループットと精度のトレードオフをもたらす。幾つかのモデル圧縮方式は精度を低下させることなしに高速化を達成している。
NNの計算システムにおけるスループットは以下の式(3)によって表される。
我々はモデル圧縮手法を用いてワークロードを削減することができる。あるFPGAチップにおいて、オンチップ上の資源は限られている。ピーク性能を増加させることは各計算ユニットのサイズの削減と動作周波数の向上を意味する。計算ユニットのサイズの削減はNNモデル内の基本的演算の単純化により達成でき、おそらくこれはそのモデル精度を低下させ、ソフトウェアとハードウェアの協調的な設計を必要とする。一方で、動作周波数の向上は純粋なハードウェア設計の仕事である。資源の高使用率の維持は適切な並列実装と効率的なメモリシステムによって生みだされる。しかし、モデル圧縮は同様にNNモデルのストレージ要求を削減し、メモリシステムに恩恵をもたらす。
エネルギー効率は、エネルギーコスト単位あたりの実行される演算数(主要なケースは乗算または加算)である。与えられたあるネットワークモデルにおける処理システムのエネルギー効率は、そのエネルギーコストと反比例する。これは計算とメモリアクセスの2つの部分からなり、方程式(4)により表される。
方程式4の初めの要素は計算に対するエネルギーコストである。この部分はモデルの圧縮に大きく影響される。モデルの圧縮はハードウェア上で実行される実際の演算数($N_{effect\_op}$)を削減し、演算の単純化は1つの演算におけるエネルギー単位を縮小する。与えられたFPGAチップに於いて、$E_{unit\_op}$もまたそのハードウェア実装に依存する。
方程式4の二つ目の要素はメモリアクセスにおけるエネルギー効率である。メモリアクセス数は$N_{mem\_access}$はそのメモリシステムとメソッドのスケジューリングに影響される。各メモリアクセスのエネルギーはより狭いビット幅を用いたモデル圧縮手法によって削減することができる。
スループットとエネルギーの分析により、NNアクセラレータはソフトウェアとハードウェアの協調的な設計を含むことが分かった。続くセクションでは過去の研究をソフトウェアとハードウェアのレベルでそれぞれ紹介する。
## 4. Software Design: Model Compression
セクション3で紹介したとおり、設計における高エネルギー効率で高性能なNNアクセラレータはソフトウェアとハードウェアによる協調設計によってもたらされる。ここではソフトウェアレベルのネットワークモデルの圧縮手法について調査を行った。この分野における多くの研究は重みの数を減らすまたは、各ニューロンや重みに用いられているビット幅を減らすことを提案している。これらは計算とストレージの複雑度を低下させる が、モデル精度を同様に犠牲にする。モデルの圧縮率と精度低下におけるトレードオフはこのセクションにて議論する。
4.1 Data Quantization
モデル圧縮における最も一般的な手法の1つは重みと入力の量子化である。よく利用されるフレームワークの内部ではNNのニューロンと重みは浮動小数点数データとして表現されている。最近の研究はこの表現を低いレベルの固定小数点データまた訓練済み値のは小さなセットに置き換えることを試みている。各ニューロンや重みに対してより少ないビット幅を用いることは、そのメモリ帯域を縮小してNN処理システムのストレージ要求を低下させる。また、一方では表現の単純化が各演算におけるハードウェアコストを削減する。ハードウェアによる利益はセクション5にてその詳細を議論するが、ここでは2種類の量子化手法を紹介する。
4.1.1 Linear Quantization
線形量子化は各重みとニューロンの最近傍な固定小数点表現を探索する。この手法の問題は浮動小数点数のダイナミックレンジは固定小数点を大きく超えていることである。そのため殆どの重みやニューロンはoverflowやunderflowに直面するだろう。Qieらは層内におけるダイナミックレンジは十分に制限されており、かつ各層間で異なることを発見した。従って、彼らは異なる層の重みとニューロンにたいして、その少数部に異なるビット幅の割り当てを行った。データのセット(1つのそうにおけるニューロンと重み)における少数部のビット幅を決定するため、そのデータ分布は事前に分析されている。可能性のある少数部のビット幅のセットが解決策の候補として選ばれ、それらのうちトレーニングセットにおける最高モデル性能を達成したものを選択する。研究では1つのネットワークにおける最適化された解決策は、膨大な設計空間の探索を避けるためにレイヤ毎に選ばれている。Guoらは全ての層における小数点ビット幅を決定した後にファインチューニングを行うことで、この手法を更に改善している。
適切な小数部のビット幅を選択する手法はデータを$2^k$のスケーリングファクタでスケールさせることと等価である。Liらは各層における訓練済みパラメータ$W^{l}$を用いて重みをスケールさせ、重みを$W^l$, 0, $-W^l$の2bitに量子化した。この研究ではニューロンは量子化されていないため、ネットワークの実装自体は32-bitの浮動小数点演算で行われている。Zhouらは層における重みを1bit($\pm{s}$)に量子化した。この$s$は$E(|w^l|)$であり、その層における重みの絶対値の期待値を取ったものである。この研究ではニューロンにも同様に線形量子化が適用されている。
4.1.2 Non-liner Quantization
線形量子化と比較して、非線形量子化は値を異なるビットコードに独立して割り当てる。非線形量子化されたコードからその対応した値への変換はまさにLUTである。この種の手法は各ニューロンと重みに用いられるビット幅を更に縮小する。Chenらは各重みに対して事前に定義されたハッシュ関数にて算出されたLUT内の値を割当てた後、そのテーブル内の値を訓練した。また、HanらはLUT内の値を、訓練済みモデルの重みをクラスタリングすることにより算出した重みに対して割当てた。各LUTの値はクラスタの中央の値のセットであり、訓練データと共に更にファインチューニングされる。この手法は精度の低下なしに、最先端CNNモデルの重みを4-bitまで圧縮することに成功した。Zhuらは層内の全ての重みを3つの値: $W^n$, 0, $W^p$に量子化した、3値量子化ネットワークを提案した。この時、量子化された値とそれに対応するLUTの値は共に訓練される。この手法はSOTAモデルとImageNetデータセットにおいて2%以下の精度のみを犠牲にし、重みを32bitから2bitに縮小した。これは16倍のモデルサイズ圧縮を意味する。
4.1.3 Comparison
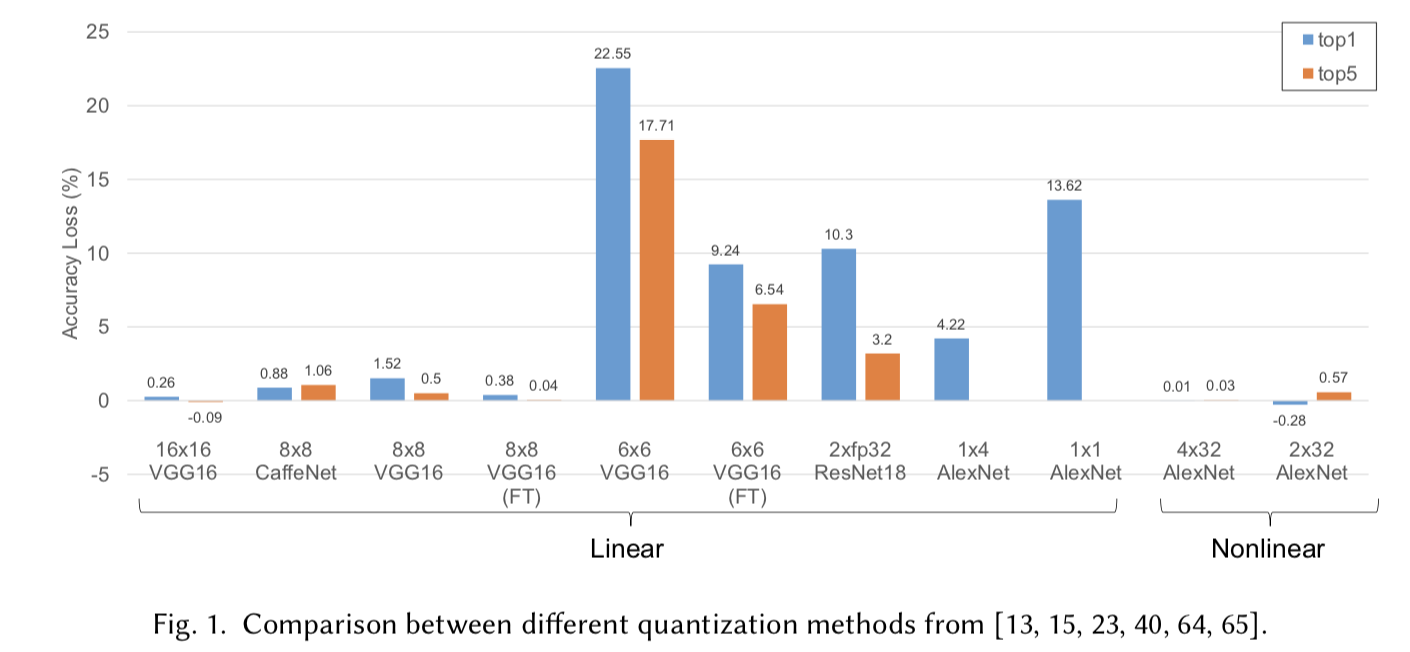
異なる量子化手法の比較を図1に示す。各ラベルはネットワークの名前とその実験したビット幅を$BW_{weight}とBW_{neurons}$で記述している。"(FT)"はそのネットワークがファインチューニングの後に線形量子化されたことを示している。異なるモデル上の異なる手法を比較することは少し不公平であるが、幾つかの洞察を与えてくれる。線形量子化に関しては、その精度低下が無視できるかどうかの明確な領域は8-bitだと言える。6またはより小さいビット幅では、ファインチューニングを用いる、または重みを初めから訓練し直した場合であっても、明らかな精度の低下を引き起こすだろう。もし1%の誤差の低下が許容できる範囲である場合、我々は8 x 8の線形量子化または2 x 32の非線形量子化が量子化における下限である。量子化による性能向上はセクション5にて議論する。
図1
4.2 Weight Reduction
ニューロン重みのビット幅を縮小する以外のモデル圧縮の手法は重みの数を削減することである。それらの手法の一種として、低ランク行列表現を用いた重み行列を近似がある。QiuらはFC層における重み行列$W$を特異値分解により、圧縮した。$m \times n$の重み行列$W$は、2つの行列$A_{m \times p}$, $B_{p \times n}$の乗算に置き換えられる。$p$が十分に小さい場合、その重みの数の合計は縮小される。この研究はわずか0.04%の分類精度の低下で、VGGネットワークの最も大きいFC層を元のサイズの36%に圧縮した。Zhangらは似た手法を畳み込み層に用いて、続く非線形層の効果を分解最適化プロセスに適用した。 提案された手法はImageNetを対象とした最先端のCNNモデルにおいて4倍の速度向上を0.9%の精度低下で達成した。
プルーニングは重みの数を削減するもう一つの手法である。この種の方法は重み内のゼロまたは、絶対値の小さいものを直接削除する。プルーニングの挑戦は、モデルの精度を維持しつつも、如何にしてより多いゼロを重み内に作るかである。1つの解は訓練中におけるlasso object functionの応用である。Liuらはspace group-lasso object functionをAlexnetモデルに適用し、1%の精度低下で訓練後の90%の重みを削除した。もう一つのゼロ重みを削除するプルーニング手法の例として、Deep Compressionがネットワーク内のゼロまたは絶対値の小さい値を直接削除した。残った重みは訓練データとともにファインチューニングされ精度を回復する。実験結果ではAlexNetにおいてモデル精度を維持したまま、89%の重みを削除可能であることを示した。重み削除により、ハードウェアはその圧縮率に応じた相互的な恩恵を受けることができる。上記の結果に伴って、重み削除からくる改善率は10倍ほどである。
5 Hardware Design: Efficient Architecture
このセクションでは、最先端のFPGAベースNNアクセラレータが高性能と高エネルギー効率を達成するために用いているハードウェアレベルの技術を調査する。これらの技術は3つのレベル: 計算ユニットレベル、ループ展開レベル、システムレベルに分類される。
5.1 Computation Unit Designs
計算ユニットレベルの設計はNNアクセラレータのピーク性能に影響する。あるFPGAチップにおいて利用可能な資源は限られているため、より小さい計算ユニット設計はより多い計算ユニットとそこからもたらされるよる高いピーク性能を意味する。もし、計算ユニットを単純化する、または実際に計算する値の数を減らすことで、注意深く設計された計算ユニットアレイはシステムの動作周波数を向上させ、ピーク性能を改善する。
5.1.1 Low Bit-width Unit
計算に利用するビット幅数の縮小は計算ユニットのサイズを直接削減する。セクション4で紹介した量子化手法は、より小さいビット幅を用いた計算を実行可能にする。殆どの最先端のFPGA設計は32-bitの浮動小数点を固定小数点に置き換える。Podiliらは提案したシステム上で32-bitの固定小数点を実装した。16-bitの固定小数点によるニューロンの設計は多くの研究で幅広く活用されている(1, 2, 3, 4, 5)。
ESEは12-bit固定小数点の重みと16-bit固定小数点のニューロンの設計を用いている。Guoらは8-bitの計算ユニットを組み込みFPGA上に実装した。近年の研究は同時に極めて小さいビット幅のデザインにも着目している。
Prost-Boucleらは3値ネットワークに対して、1つのLUTで2-bitの乗算を実装した。FPGAとCPU、GPU、ASICを比較した実験では、BNNのFPGAの実装はCPUとGPUよりも大幅に優れていることを示した。BNNはこれまでその精度低下に悩まされて来たが、多くの研究が1-bitを計算に用いることの恩恵を探索してきた(1 , 2, 3, 4, 5, 6, 7)。
上述した計算ユニットと線形量子化に着目している。非線形量子化においては、データを単精度に変換した後でドット積を行うため高コストである。Samrageらは因数分解係数を基にしたドット積実装を提案した。非線形量子化におけるとり得る重みの値が極めて限られている時、提案されている計算ユニットはそれらの値の組み合わせの積をLUT内の値の重み付けされた和として計算する。この方法を用いると、一つの出力を得るための上記の乗算はLUT内の値の数に等しく、元の乗算はランダムアクセスのアキュムレーションに置き換えられる。
これらのデザインの多くはNNの計算処理を通して、等しいビット幅を利用している。QiuらはFC層におけるニューロンと重みに対し、その精度を保持しながら畳み込み層と比較してより小さいビット幅を用いた。研究(1, 2)は混成計算ユニットを用いている。
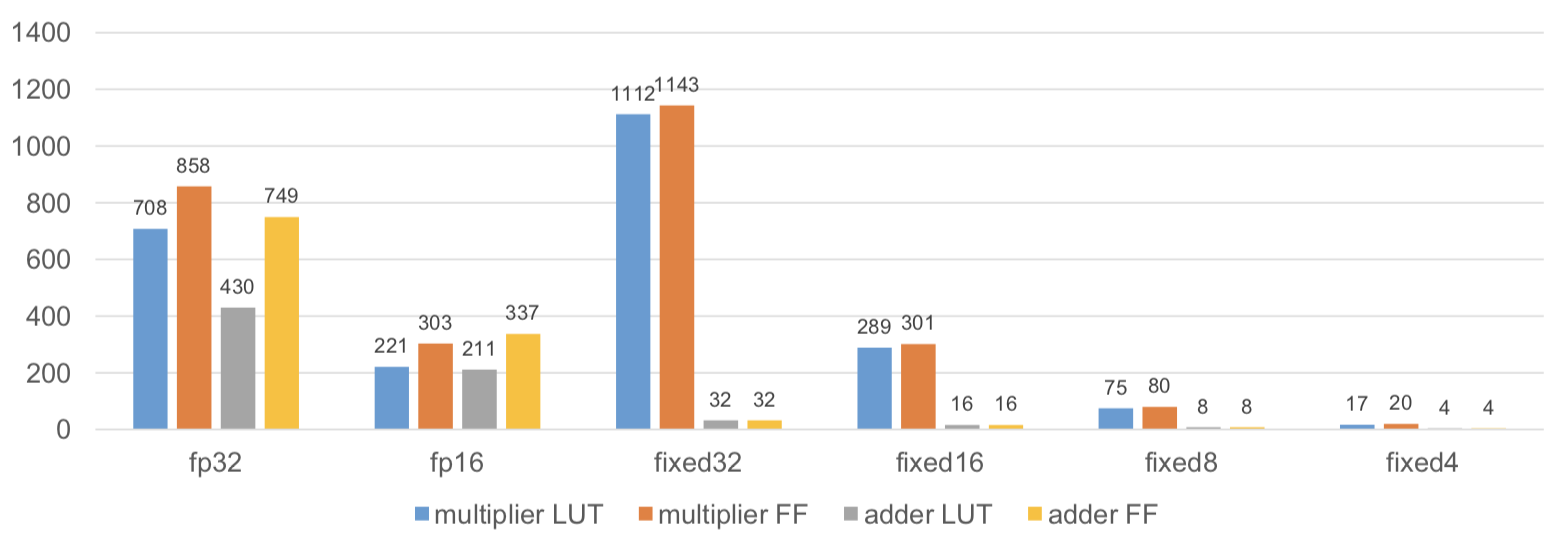
異なるビット幅における計算ユニットのサイズを図2に比較している。リソース使用率はVivado2017.2での合成結果を元にしている。全てのIPはDSPを利用する必要がない。実際の実装ではDSPを利用する傾向があるにも関わらず、この結果は実際のリソースを示している。また、ハイブリットな手法を用いて計算ユニットを実装することもよく行われており(上記のQiuらの研究)、これらでは幾つかの演算がDSPと他のロジックを組み合わせて実装されている。
NNにおいて、乗算と加算の数はほぼ同じに扱われる。従って、乗算と加算に対するリソースの合計が全体のコストとなる。32-bit固定小数点演算は32-bit浮動小数点演算と似通った量のリソースを消費する。16-bit固定小数点演算はリソースを30%節約できる。セクション4.1で、8-bit固定小数点が線形量子化の限界だと述べた。これは32-bitの場合と比較すると、同じロジック領域において14倍のハードウェア演算を行うことができる。もし、さらなる研究で4-bitの演算を活用できる場合、このアドバンテージは54倍になりうる。また1-bitのデザインは1000倍を上回る改善が可能である。
図2
5.1.2 Fast Convolution Unit
畳み込み層において、その畳込み演算を特別なアルゴリズムによって高速化することができる。離散フーリエ変換(DFT)を基にした高速畳み込みはDSPの領域で広く用いられている。Zhangらは2DのDFTベースのハードウェア設計による畳み込み層の効率的な実行を提案した。1つの$F \times F$のフィルタが$K \times K$のフィルタと畳み込まれる時、DFTは空間領域における$(F - K + 1)^{2}K^{2}$の乗算を、周波数空間における$F^2$の複素乗算に変換する。これは高々$(M + N)$回のDFT/IDFTが必要とされる一方で、$M$チャンネルの入力と$N$チャンネルの出力を持つ畳み込み層において、$MN$回の周波数領域乗算が必要となる。畳み込みカーネルの変換は全体を通して一度だけで良い。従って、各畳み込み層におけるドメインの変換処理は低コストである。この技術はストレイドが1 x 1より大きい場合、機能しない。Dingらはブロックごとの巡回制約が重み行列に適用できることを示唆し、全結合層における行列ベクトル乗算が一次元畳み込みのセットに変換して、周波数領域で更に高速化できることを示唆した。この手法は$K \times K$の畳み込みカーネルを$K \times K$の行列として扱うことで畳み込み層にも同様に適用可能であり、$K$自体やストライドにも制限されない。
周波数領域手法が複素数の乗算を必要する一方で、実数の乗算のみを含む高速畳み込みの別の手法としてWinogradがある。Winogradアルゴリズムを用いた、カーネル$K$と2次元特徴マップの畳み込みは以下の方程式で表される。
$G$、$B$、$A$はそのカーネルサイズと特徴マップに関連するだけの変換行列である。$\odot$は2つの行列の要素ごとの乗算を示している。$3 \times 3$のカーネルと$4 \times 4$の特徴マップの畳み込みにおける変換行列の例は以下のようになる。
WinogradもDFTベースの手法と同様に、カーネルサイズとストライドに制限を受ける手法であり、最もよく用いられるWinograd変換は$3 \times 3$畳み込みである(1, 2)。
高速畳み込みから来る理論的な性能の向上はカーネルサイズの変形に依存する。DFTベースの手法が複素乗算やより多くのハードウェアを必要とすることから、我々は$6 \times 6$Winograd における理論的な速度の向上は4倍と見積もっている。
5.1.3 DSP Optimization
近年のFPGAはより高い計算性能を提供するために、を再構成可能なロジックの他に内部にDSPユニットを実装している。DSPユニットの基本的な機能はMAC(Multiplication Accumulation)であり、その乗算と加算におけるビット幅は固定である。NNに用いられるビット幅がDSPユニットのビット幅と合わない時、FPGAを完全に活用することはできない。Altera FPGAにおける最新のDSPユニットは$18 \times 19$の乗算器を実装しており、これは$27 \times 27$または32-bit浮動小数点の乗算器に再構成可能である(参照: Stratix10)。Xilinx FPGAでは、1つで$27 \times 18$の乗算器を実装している(参照: UltraScale)。セクション5で述べたように、多くのデザインが16-bitもしくはそれ以下のビット幅を乗算に採用しており、DSPの利用効率が減少する可能性がある。
Nguyenらは2つの狭いビット幅の固定小数点乗算を1つの広いビット幅の固定小数点乗算器で実装するデザインを提案した。この中で、$AB$と$AC$は1つの乗算として実行される($A(B << k + C)$)。もし、$k$が十分に大きければ、$AB$と$AC$のビットは乗算結果の内部で重複することなく直接分離できる。このデザインは2つの8-bit乗算を1つの$25 \times 18$ビットの乗算器と$k = 9$を用いて実装されている。似た手法が異なるビット幅やDSPに対しても適用可能である。この技術を用いると理論的な性能のピークを2倍に引きあげることができるが、エネルギー効率の面では恩恵を受けることができない。なぜなら、$E_{unit_op}$は変化していないからである。
5.1.4 Frequency Optimization Methods
上述した全ての技術は、あるFPGA上に於ける計算ユニットの数を向上させることに注目しているが、計算ユニットの動作周波数を増加させることもまたピーク性能を向上させる。NNアクセラレータは高い並列性を実装するため、基本的な演算としてベクトル内積演算器よりむしろ、行列-ベクトル乗算器または行列-行列乗算器をよく実装している。異なる計算ユニットは演算を共有する。異なる計算ユニットに対する単純なデータのブロードキャストは面積の拡大と高いルーティングコストに繋がり、動作周波数の低下を招く。Weiらはシストリックアレイ構造を用いた。これは連鎖モードで共有データを1つの計算ユニットから次の計算ユニットへ伝達する事ができる。従って、共有データはブロードキャストされることなく、必要な計算ユニット間のローカルな接続によってのみ伝達される。NNモデルの計算処理は事前に決定しているため、シストリックアレイ構造は完全にパイプライン化され、そのレイテンシは十分に隠蔽できる。
最新のFPGAは理論値700-900MHzの周波数で動作可能なDSPをサポートしている(Xilinx UltraScale (741 MHz), UltraScale+ (891 MHz))が、既存のデザインは100-300MHzしか活用されていない。Xilinx Wuらの研究内で述べられているように、動作周波数はオンチップSRAMとDSPユニットの間のルーティングにより制限されている。上記研究ではDSPとその周囲のロジックに対してに異なる動作周波数を用いる設計を用いている。ローカルRAMを各DSPユニットと隣接したスライスとして独立したクロック領域で用いたプロトタイプは、DSPが異なるスピードグレイドのFPGAチップにおいてピーク動作周波数(741MHzと891MHz)で動作することを達成した。この手法は完全なNNアクセラレータのデザインとしては採用されていないが、この技術を用いない既存デザインが300MHzで動作していることを考慮すると、その理論上の向上率は2倍である。
5.2 Loop Unrolling Strategies
畳み込み層と全結合層はNNに於ける計算とストレージ要求の殆どを占めている。畳み込み層をネストしたループのアルゴリズム1として以下に示す。コードを綺麗に記述するため、以下では特徴マップと畳込みカーネルのそれぞれにおけるxとy方向のループを結合している。全結合層は特徴マップとカーネルサイズが$1 \times 1$の畳み込みとして扱うことができる。アルゴリズム1の他に、複数の入力に対する処理の並列性をバッチと呼び、その形式をバッチループとする。

ループの実行を並列化するために、ループのある部分をアンローリングし、その部分のすべての演算をハードウェア計算ユニットで行う。適切でないループアンロールパラメータのセットは、深刻なハードウェアの非効率的活用をもたらすだろう。以下の大きなキューブはループに含まれる全ての演算を表し、各辺の長さは任意のループのトリップカウントを示している。また、小さなキューブはアンローリングされたカーネルを意味し、そのエッジはアンローリングパラメータを表している。完全なワークロードの実行は、大きなキューブが小さなキューブによってはみ出すことなく埋められることを意味する。図3は1つのアンローリングされたパラメータのセットを示している。この場合、図3(b)内にある、赤い幾つかの小さなキューブは大きなキューブの外にあり、これはハードウェアが無駄になることを意味している。
図3
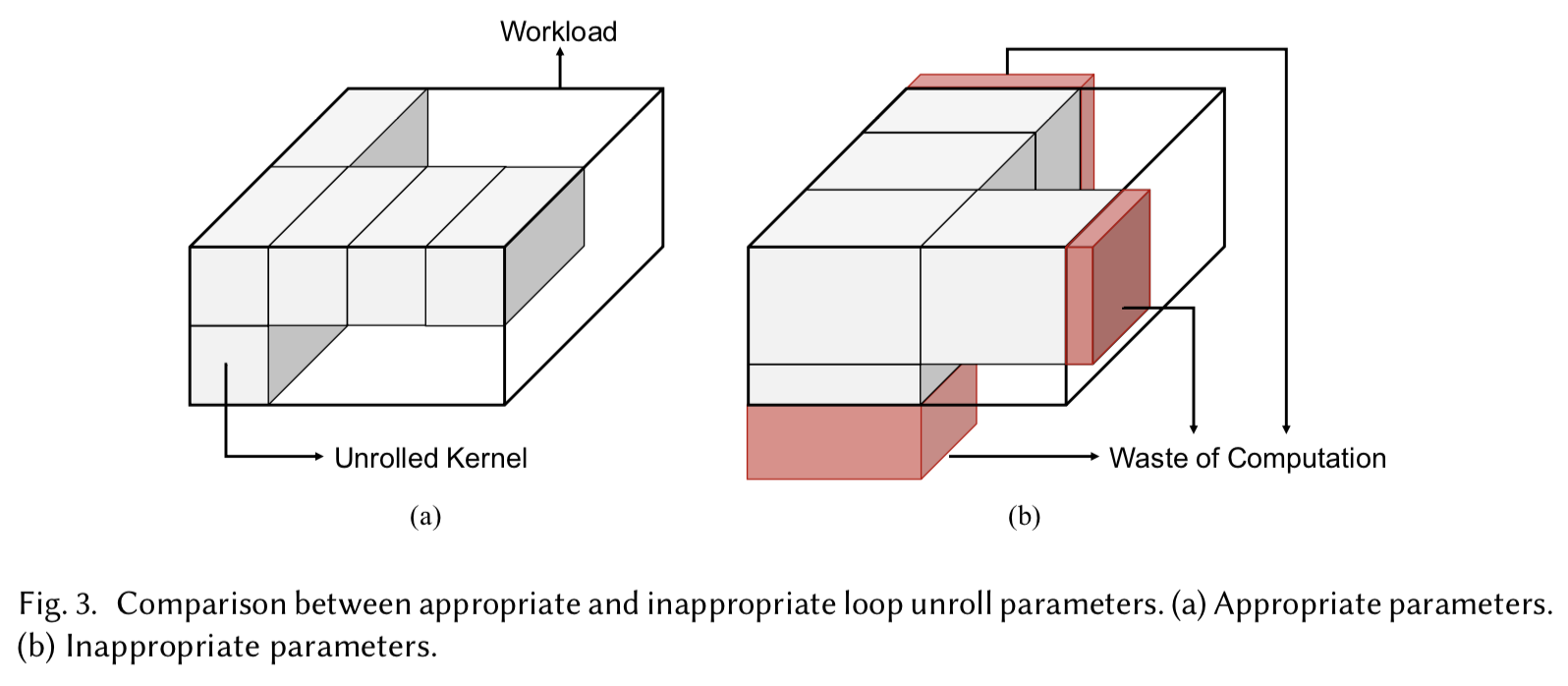
図3から明らかなように、ループのトリップカウント小さすぎる場合はアンローリングパラメータは制限される。CNNモデルに対して、そのループの次元は層によって大幅に異なる。ResNetのようなImageNetを用いている主要な分類ネットワークにおいて、そのチャンネルの数は3から2048、特徴マップのサイズは$224 \times 224$ から$7 \times 7$、畳込みカーネルのサイズは$7 \times 7$から$1 \times 1$というバリエーションがある。低利用度の問題の他に、アンローリングはそのデータパスとオンチップメモリデザインにも同様に影響を与える。このループアンロール戦略はNNアクセラレータ設計における鍵となる特徴である。
これまで、いかにしてアンロールパラメータが選ばれるべきかに焦点を当てた様々な研究が提案されてきた。Zhangらは入力チャンネルの出力チャンネルループをアンローリングすることを提案し、設計空間の探索により最適化されたアンローリングパラメータを選択した。これら2つのループにおいて、隣接する反復間に入力データの相互依存性は存在しない。従って、データをオンチップバッファから計算ユニットへルーティングするためのマルチプレクサを必要としない。しかし、その乗算の並列性は$7 \times 64 = 448$と限られているため、より多くの並列化の際には容易に低利用度問題が発生する。Maらは特徴マップループ上での並列化を可能にすることで、設計空間の更に拡張した。その並列性は$1 \times 16 \times 14 \times 14 = 3136$に登り、シフトレジスタ構成が特徴マップピクセルを計算ユニットへのルーティングに利用された。
上述した研究ではカーネルのループは考慮されていない。なぜならカーネルのサイズが大きく異なるためである。MotamediらはカーネルのアンローリングをAlexnet上で持ちいた。$11 \times 11$と$5 \times 5$のカーネルにおいて、$3 \times 3$のアンローリングを行う場合でも、畳み込み層におけるシステム全体の性能は97.4%に達する。一部のVGGのようなネットワークには$3 \times 3$カーネルのみが利用されている。Qiuらは$3 \times 3$のスライディングウィンドウ関数を実装するために、ラインバッファ構成を用いて、カーネルループを完全に並列化した。カーネルループをアンローリングする別の理由は高速畳み込みアルゴリズムのためである。Zhangらの研究では、$4 \times 4$の特徴マップと$3 \times 3$のカーネルにおける周波数領域乗算が完全に並列化されて実装されている。Luらは、方程式(5)に特化したパイプライン でWinogradアルゴリズムをFPPG上に実装し、$6 \times 6$カーネル上における$3 \times 3$カーネルの畳込みは完全に並列化されいる。
上記の解決策は、単一の層にのみ適用されるが、ネットワーク全体に対して、特に高い並列性が必要な場合には、1つのサイズが全てに適用できることは殆ど無い。デザイン12では各層に対して完全にパイプライン化された構造を提案している。各層がハードウェアの独立した部分で実行可能で、かつそれらが小さい場合、ループのアンローリングを容易に選択できる。この手法はピンポンバッファが隣接した層間で必要となるため、メモリを消費し易い。この研究では先の研究と類似しているが、スケーラビリティの問題を解決するためにFPGAクラスタに実装されている。ShenらはCNNの幾つかの層をループのトリップカウントによりグルーピングし、各グループを1つのハードウェアモジュールに割当てた。実際にこれらの手法では、異なる入力が異なるレイヤのパイプラインステージで平行に処理されるため、バッチループのアンローリングとして扱うことができる。WinogradのFPGA実装の研究では、1つの層とその周りの異なる層でバッチの並列処理を実装している。バッチ並列手法の欠点は、同様の並列度においてバッチサイズが1の場合と比べてレイテンシが高くなることである。
現在のデザインの殆どが、上述したループアンローリングの手法のどれか1つを用いているが、特別な種類のデザインのとしてスパースNNへへの対応がある。HanらはスパースLSTMネットワークの高速化において、ESEアーキテクチャを提案した。デンスネットワークの処理とは異なり、全ての計算ユニットが同期的に動くことはなく、異なる計算ユニット間におけるデータ共有を困難にする。ESEはハードウェア設計の単純化のため、1つのレイヤ内で出力チャネル(LSTM内の全結合層の出力ニューロン)ループのみをアンローリングして、バッチ処理の並列化を行うように実装されている。
5.3 System Design
典型的なFPGAベースのNNアクセラレータシステムは図4の様になっている。青いボックスがシステム全体のロジック部分を指しており、このホストCPUはワークロードもしくはコマンドをFPGAのロジック部分に発行して、その動作状況を監視する。FPGAのロジック部分には多くの場合ホストとの通信用コントローラが設置されており、FPGA上の他の全てのモジュールに対して制御信号を送信する。コントローラはFSMまたは命令デコーダを持つ。 on the fly logic パートは、プリプロセスが必要なデータが外部DRAMから読み込まれるデザインのために実装されており、データの並び替えやシフタ、FFT等のモジュールとして利用できる。
図4
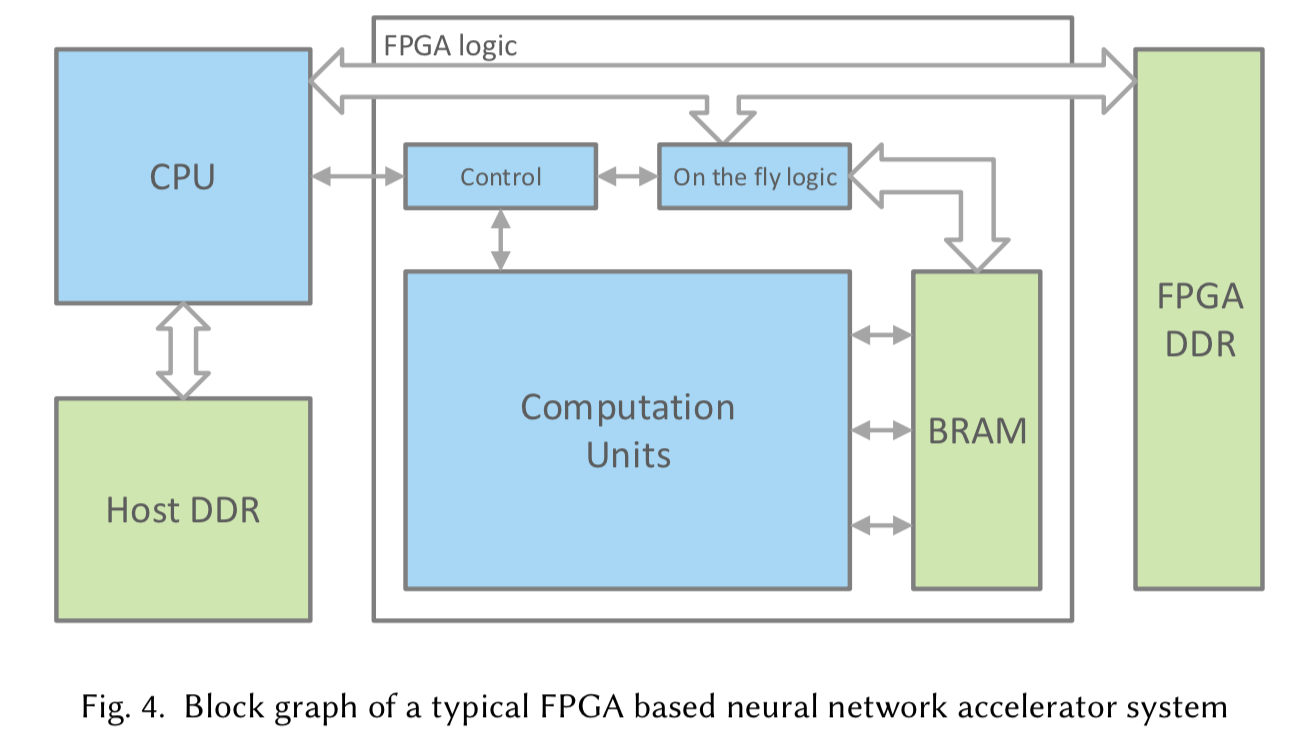
システムのメモリ階層は、図4に緑の四角で示されているHost DDR, FPGA DDR, オンチップメモリの3つの主要な要素を含んでいる。最先端のネットワークにおいて、その重みは100MBに及ぶることがある。8-bitやより低いビット幅に量子化を行った場合でも数十MBのストレージが要求される。現状のFPGA実装の殆どが10MB以下のオンチップメモリと1-8GBの外部DDRをボード上で統合したシステムとなっているため、一般的なシステムではDDRとオンチップメモリという2レベルのメモリ階層が用いられる。
システムレベルにおいて、NNアクセラレータの性能はオンチップの計算資源量とオフチップメモリ帯域の2つによって制限される。特定のオフチップメモリ帯域間において最適な性能を達成するために様々な研究がなされてきた。Zhangらはそのデザインがメモリバウンドと計算バウンドのどちらであるのかを分析するために、ループラインモデルを導入した。ルーフラインモデルの例を以下の図5に示す。
図5
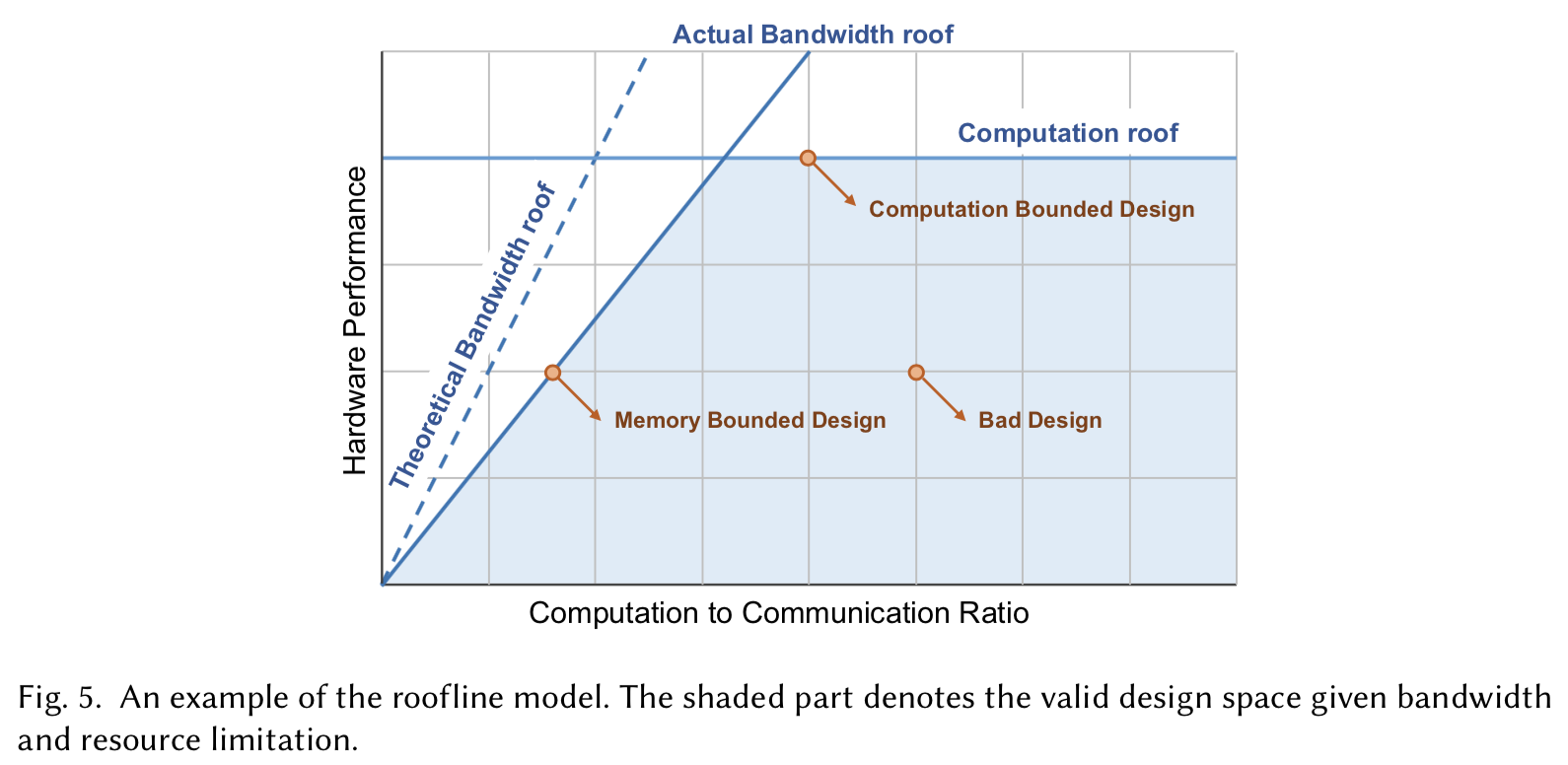
この図のx軸は演算通信比(Compuatation to Communication: CTC)比を、y軸はハードウェア性能を表している。CTC比はメモリアクセス単位あたりで実行可能な演算回数を表しており、各ハードウェア設計は図内部の点として表わされる。$y / x$はメモリ帯域の要求と等しい。あるプラットフォームが与えられた時、その利用可能な帯域は制限されており、図5内の理論的帯域上限により記述することができる。しかしDDRアクセスにおいて、その利用可能な帯域はデータアクセスパターンに依存し、実際の帯域上限は理論値よりも低くなる。例えばシーケンシャルなDDRアクセスではランダムアクセスよりも高い帯域を得られることが多い。もう一つの上限は計算上限であり、FPGA上で利用可能な計算資源により制限される。
より高いCTC比は、そのハードウェアが計算バウンドであることを意味する。CTC率を向上させることで、DDRアクセスを減らすことも可能であり、その上昇度合いに伴いエネルギーコストを大幅に削減する。セクション5.2で任意のネットワークに対する計算の無駄を減らすためにループアンローリング戦略について議論した。ループアンローリングの戦略を決定する際に、ループの残りの部分のスケージュールがどのようにハードウェアがそのオンチップバッファ内のデータを再利用可能なのかを決定する。これはループタイリングやループインターチェンジの戦略を含む。
ループタイリングは高レベルのループアンローリングである。ループタイルにおける全ての入力データはオンチップに格納され、ループアンローリングハードウェアのカーネルはそれらの上で動作する。より大きいループタイルサイズは各タイルが外部メモリからオンチップメモリにより少ない時間で格納できる。ループインターチェンジ戦略はループタイルの処理の順番を定め、そのハードウェアが1つのタイルから別のタイルに処理を移す際に外部メモリアクセスが起こる。隣接したタイルはデータの一部をシェアする。例えば1つの畳み込み層において、隣接したタイルは入力特徴マップまたは重みを共有することができる。これはそのループの実行順序によって決まる。
研究(1, 2)では、可能性のある全てのループタイリングサイズやループ順序におけるデザイン空間探索がなされている。また、多くのデザインが既に決められた幾つかのループアンローリング、タイリング、ループ順序を元にデザイン空間の探索を行っている(1, 2)。ShenらはCTC比を通して、異なるレイヤにおけるバッチ並列化の効果を議論した。
上述した研究は1つの最適化されたループアンローリング戦略とネットワーク全体のループ順序を提供する。AngelEyeは異なる層に対して、柔軟性のあるアンローリングとループ順序の設定を命令インターフェイスを用いて実装した。これはオンチップメモリのバッファサイズに応じた最大のタイリングサイズを持ちるため、ハードウェアが常にオンチップバッファを活用できることを意味する。この研究は最も内側のループ終了時のオンチップデータの完全なリフレッシュを避けるため、"back and forth"ループ実行オーダという手法も提案している。
Alwaniらは外部メモリアクセスの問題に対して、2つの隣接した層を融合させることで、2つの層間で中間結果を伝送すること避ける提案を行った。この戦略は20%のオンチップメモリコストの追加により、95%のオフチップメモリへのデータ転送を削減い、かつソフトウェアプログラムの速度を2倍に向上させる。
CTC比の向上以外に、実際のバンド幅の増加させることで、あるCTC率における達成可能な性能を向上させることができる。これはDDRアクセスのアクセスパタンを正則化することにより実現する。外部メモリ内の標準的なデータフォーマットとは"NCHW"もしくは"CHWN"である。Nは特徴マップにおけるバッチの次元、Cはチャネル次元、HとWは高さと幅である。これらの任意のフォーマットを用いることで、特徴マップのタイルは非連続なアドレスを持つ小さなデータブロックに分割して格納される。GuanらのFP-DNNではチャネルメジャーなストレージフォーマットを使うべきであることを示唆した。このフォーマットは、長いDDRへのバーストアクセス保証されている間でそのデータの重複を回避できる。Qiuら(Going deeper...)は$H \times W$の特徴マップを、サイズ$r \times c$を持つ($HW/rc$)タイルブロックに並べ替えるフォーマットを提案した。これにより、そのライトバーストサイズを$c/2$から$rc/2$に増加することが可能になる。
6. Evaluation
このセクションでは、最先端NNアクセラレータの性能の比較とセクション4と5で述べた技術の評価を行う。比較に用いた各デザインを以下のテーブルに示す。"A/B"はA-bitの固定小数点のニューロンとB-bitの固定小数点の重みが用いられていることを示す。また、リソース使用量の調査を行い、アクセラレータ設計者とFPGAメーカの双方に助言を提供する。
テーブル1における各デザインは、図6内の点としてx軸を$\log_{10} power$、y軸を$log_{10} speed$として描かれている。FPGAデザインの他に、研究(Angel-EyeとESE)におけるGPUの実験に基づいた結果も性能測定のための標準として同様にプロットした。
セクション4.1で述べたように、1-2-bitの線形量子化ネットワークモデルは大幅な精度低下に悩まされているため、単純なタスクにのみ適用されている。そのエネルギー効率は32-bitの浮動小数点デザインと比較して、100倍改善されるが、依然としてその改善率の見積もりである1000倍と比較すると依然としてギャップがある。これはメモリアクセスが1-2bitデザインのボトルネックとなっていることを示している。これはそのビット幅に対して線形にしか増加しない。INT16/8かINT16またはINT8はよく用いられるが、それらの違いは余り顕著ではない。これは現状のFPGA実装の多くが$18 \times 25$または$18 \times 18$のDSPを乗算器として用いているという事実に起因するためである。DSPに対してはより小さいビット幅を計算に用いることの恩恵はない。二重MACの技術がこの解決策として提案されているが、以下にリストアップされたデザインには適用されていない。
テーブル1
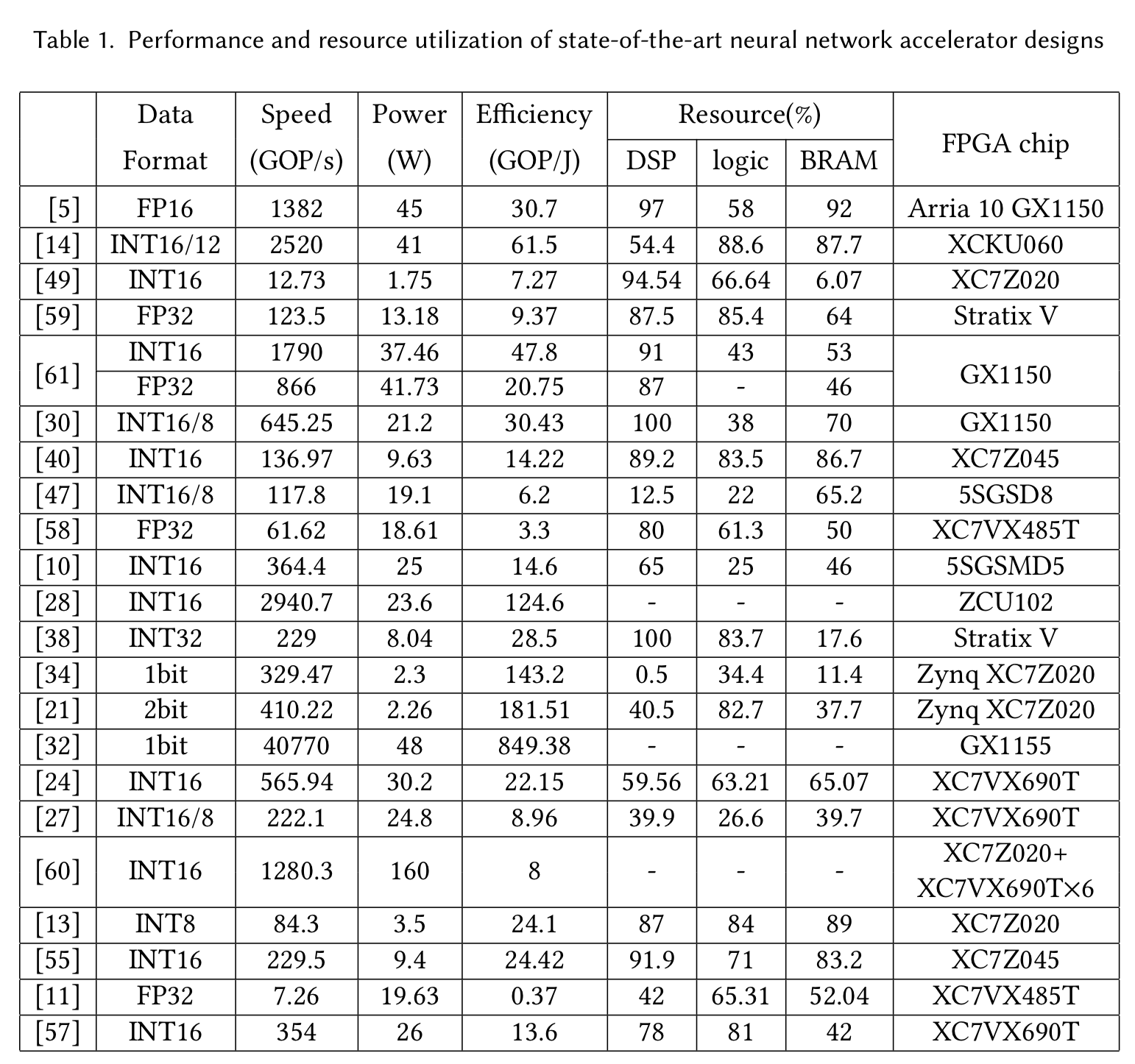
図6
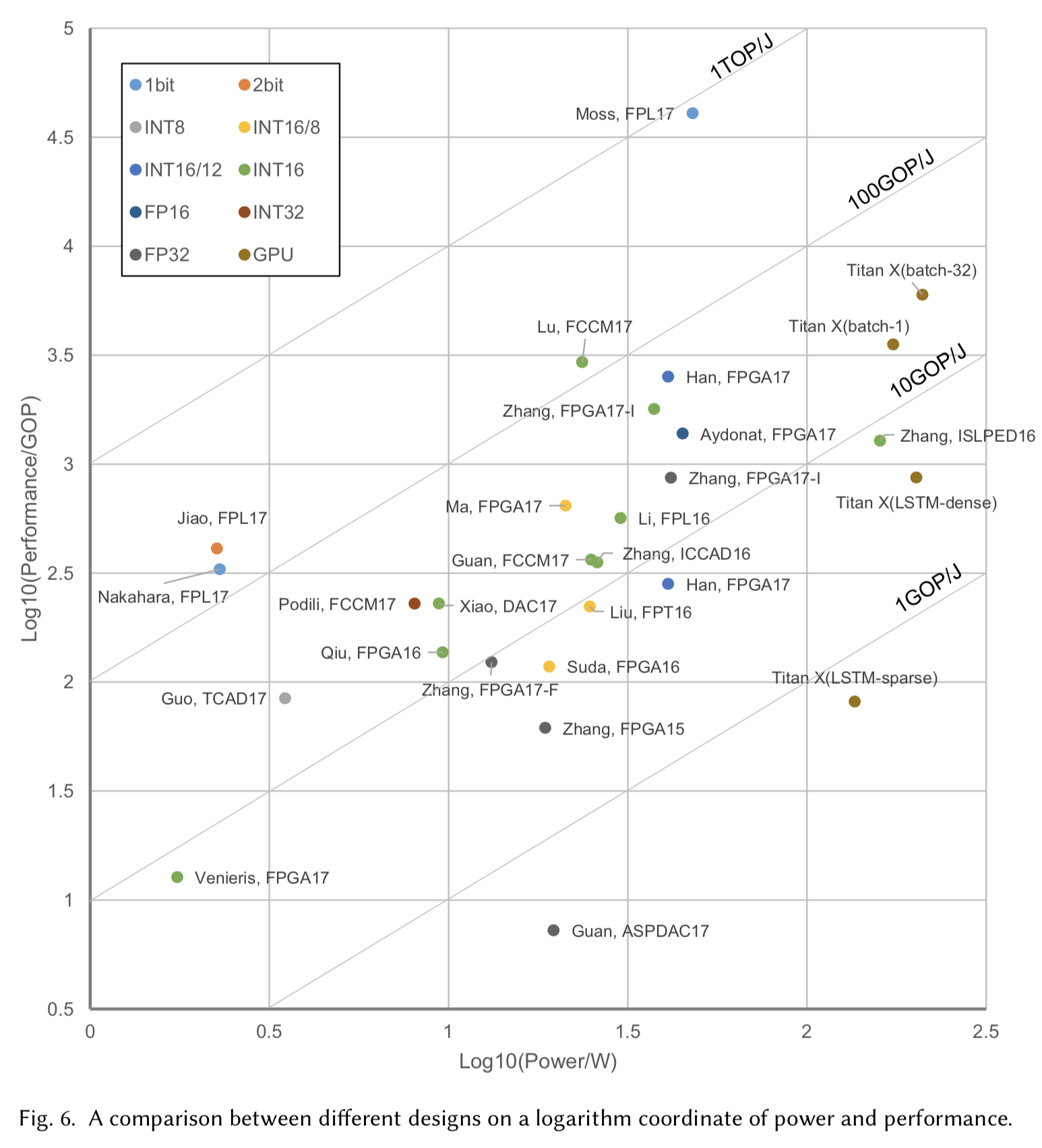
6.0.2 Fast Convolution Algorithm
16-bitデザインの中で、$6 \times 6$Winogradによる高速畳み込みの設計が最も良いエネルギー効率と最高速度を達成した。これは他の16-bitを用いたアクセラレータデザイン(OpenCL)より1.7倍高速かつ2.6倍のエネルギー効率を達成した。FFTによる高速畳み込みデザインは2倍の高速化と3倍のエネルギー効率を32-bit浮動小数点デザインに対して実現した。
6.0.3 System Level Optimization
殆どの研究の中で、システム全体の最適化に注力しているものはあまりない。これはHLDデザインの質により関係してくるため、我々はその効果だけを大まかに評価した。ここでは1, 2, 3の3デザインを、xilinx XC7VX69Tプラットフォームの上で評価した。これら3つのデザインは2を除き、16-bit浮動小数点データフォーマットを採用しており、2は8-bitを重みに用いている。これらでは高速畳み込みやスパース実装は行われていないが、1は2の2.5倍のエネルギー効率を達成している。これはシステムレベルの最適化が、高速畳み込みアルゴリズムの仕様以上に強い効果を持つことを示している。
我々はテーブル1におけるデザインのリソース使用量も同様に調査した。ここではDSP, BRAM, logicの3つの種類のリソースが考慮されており、図7にそのうちの2つのリソース使用率をxとy座標にプロットした。各図の上にはハードウェアリソース上でのデザインの性能を示すための対角線を引かれている。例えばBRAM-DSPの図では、ハードウェア上においてBRAMよりDSPが好まれていることが分かる。また、同様の隔たりがDSPとlogicの間でも見て取れる。これは現状のFPGAデザインが計算バウンドであることを示している。従って、NNアクセラレータを対象とするFPGAメーカはこれらの傾向にそって資源の分配を調整することができる。
図7
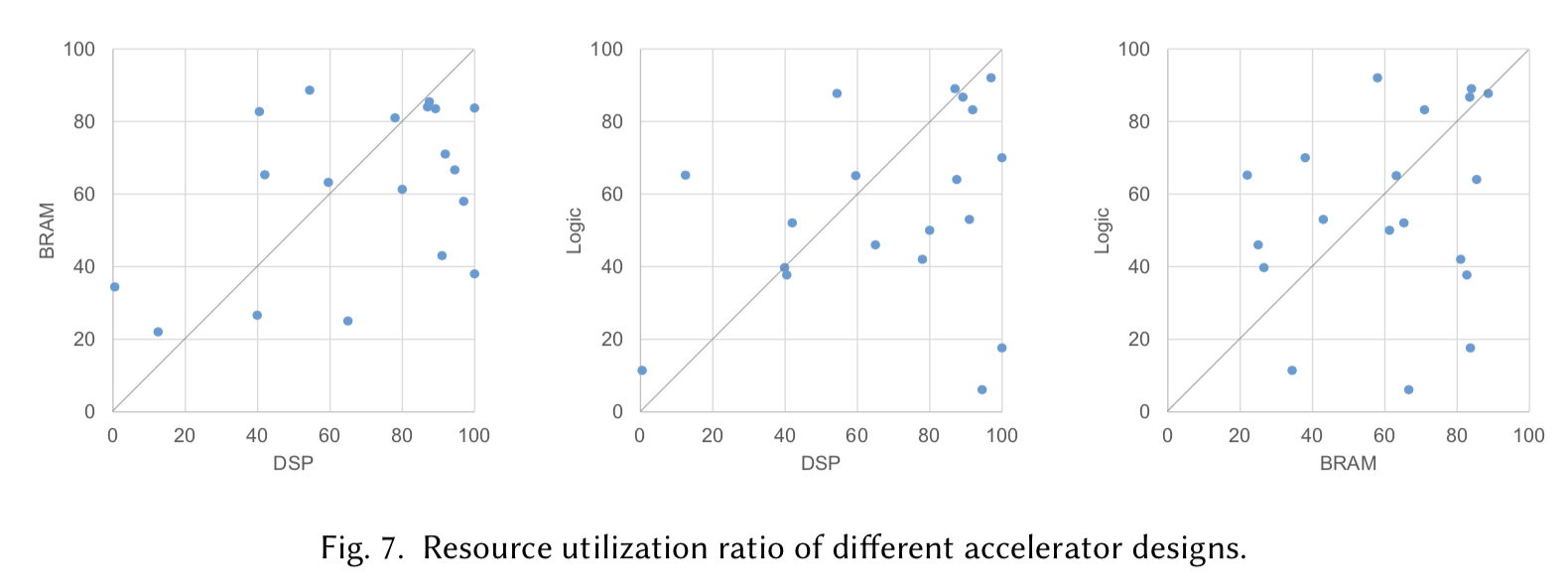
6.0.4 Comparision with GPU
一般的にFPGAベースのデザインは、エネルギー効率において10-100GOP/JというGPUに対して比較可能な結果を達成しているが、速度面ではGPUが勝っている。FPGAベースのデザインのスケールを上げるためには依然として問題がある。Zhangらは16-bit固定小数点計算を持ちいたFPGAクラスタベースのソリューションを提案したが、このエネルギー効率は他の16-bit固定小数点デザインよりも悪い。
ここで理想的デザインが達成可能な性能を見積もることにする。ベースラインとして32-bitの浮動小数点デザインを用いる。まず、セクション4.1の分析に伴って、8-bitの線形量子化を用いると14倍のエネルギー効率と高速化を実現できる。その後高速畳み込みと周波数最適化で更にそれぞれ4倍と2倍の向上が見込める。セクション4.2のデータのプルーニングによる10倍を改善を考慮すると、約1000倍の高速化と500倍のエネルギー効率を達成できる。たとえ100倍という保守的な見積もりを用いたとしても、このシステムは80TOP/sと80Wの電力消費が達成可能であり、これは1TOP/Jにも上り、最新GPUにおける32-bitを用いた浮動小数点演算の実装を一桁上回る。
7 Design Flexibility
これまでは高速度と高エネルギー効率を実現するために用いられている技術について議論してきたが、それらの殆どが特定のネットワークに注力している。このセクションでは、異なるネットワークモデルおよび対応する開発ツールにニューラルネットワーク設計を適合させるために使用される手法について議論する。開発ツールほとんどはCaffeのprototextファイルのようなネットワークモデルレベルのインターフェイスを入力として実装している。ハードウェアの柔軟性においては、HDLモデルベースと命令ベースの2つの主な手法が用いられている。
7.1 HDL Model Based Method
HDLモデルベースの手法はFPGAベースのアクセラレータで多く用いられている。これらの提案技術はネットワークのパラメータに応じてHDLを自動で生成する。これらの手法では、高レベルのネットワーク記述と低レベルのハードウェアデザイン間のギャップを埋めるためのネットワークの中間レベル記述は異なっている。
中間記述を用いない直線的な方法として、Yufeiらのデザインフローは、プラットフォームの制約とネットワーク記述の入力からハードコードされたverilogテンプレートの最適なパラメータを探索する。この手法はセクション5で述べた最適化手法と似通っている。DiCeccoらはOpenCLモデル基にして似た考え方を用いた。これはその開発環境をCaffeと統合し、Caffeと任意のネットワークを異なるプラットフォーム上で実行可能にした。
[Venireisら][http://ieeexplore.ieee.org/document/8056828/]はネットワークモデルをその設計ツール内のDFGとして記述し、ネットワークの計算処理はDFGマッピング手法としてハードウェア設計に変換される。
DnnWeaverは仮想の命令セットをネットワークの記述に持ちいており、ネットワークモデルは初めに命令のシーケンスへと変換される。その後、そのシーケンスはハードウェアのFSMとしてマッピングされるが、伝統的なCPU命令のようには実行されない。
HDLモデルベースの手法はハードウェアデザインを各ネットワークへと直接変更する。これはハードウェアが常に対象のデバイスに対して最適な性能を達成することを意味する。これはFPGAの再構成可能 という特性に適していると言え、ネットワークが頻繁に変更されないような状況であれば再構成のためのオーバヘッドも問題にならない。例えば、大規模なクラウドサービスであれば、そのネットワークモデルの変更は異なるFPGAにスイッチすることでカバーすることができる。この場合、各FPGAは頻繁に再構成されることはない。
7.2 Instruction Based Method
命令ベースの手法は異なるネットワークを同一のハードウェア上で動作させることに挑戦している。これらの研究の異なる点は命令の粒度である。より低いレベルにおいて、Angel-EyeはLOAD, CALC, SAVEの3種類の命令のみを含んだセットを提案している。LOADとSAVE命令の粒度はデータのタイリングサイズと同じであり、各CONVが命令にエンデコードされた特徴マップのサイズに対して、2D畳み込みのセットを実行する。そのチャンネル数はハードウェアのアンロールパラメータに対して固定である。このレベルにおいて、ソフトウェアコンパイラは静的なスケジュールと動的なデータの再利用戦略をそのレイヤに応じて実行することができる。
Caffeineは層レベルの命令を利用する。CNN層の制御は再構成可能なハードウェアFSMで設計される。Angel-Eyeと比較して、このデザインは再構成可能FSM上のハードウェアコストが上昇する一方で、命令アクセスのためのメモリのアクセスを削減する。
命令ベースの手法はハードウェアを変更しないため、ランタイムでネットワークを変更することを可能にする。アプリケーションのシナリの例として、モバイルプラットフォーム上におけるリアルタイムのビデオ処理システムがある。もしこのシステムのタスクが十分に複雑である場合、1フレームの処理が異なるネットワークを含む可能性がある。この場合、再構成可能なハードウェアは許容できないオーバヘッドを引き起こす可能性がある。命令べースの手法であれば、全てのネットワークにおける全ての命令がメモリ内に用意しておくことで、この問題を解決できる。
7.3 Mixing Method
Wangらは、ハードウェア設計の最適化とソフトウェア命令のコンパイルをの双方により、上記の2つを混合した手法を提案した。そのハードウェアは初めに、最適化されたハードウェアパラメータを用いて定義済みHDLテンプレートを組み合わせて構成される。その計算処理のデータ制御フローはソフトウェアバイナリにより行われ、ネットワーク記述に応じてコンパイルされる。これは単純なソフトウェアバイナリの変更により、ハードウェアを新しいネットワーク対して利用可能にすることを可能にする。
8. Conclusion
本稿では最先端のNNアクセラレータの設計をレビューし、その技術をまとめた。セクション6の評価結果より、ソフトウェアとハードウェアの協調設計を用いる場合に保守的に見積もったとしても、FPGAは最先端のGPUより13倍良いエネルギー効率を達成し、電力を30%に抑えることができる。これはFPGAがNNアクセラレータの有望な選択肢であることを示している。また、柔軟性のあるアクセラレータを設計するために用いられている技術も述べ、これらは現状の開発フローが高性能を達成しつつも、ランタイムにおいてネットワークを変更可能であることを示している。
しかしながら、現状のデザインとその見積もりの間には依然として大きなギャップが存在する。全ての技術を組み合わせることはソフトウェアとハードウェアの協調設計を必要とする。性能を保ちながら量子化と重みの削減を共に用いることは挑戦的であり、そのデザインをスケールアップすることもまた別の課題である。今後の研究はこれら3つの問題を解決すべきである。1/2-bitをニューロンや重みの表現に用いることには依然として10倍の性能上昇可能性があり、今後の研究はこのケースにおける精度向上にも同様に挑戦するべきであろう。
コメント
コメントを投稿