VTA: An Open Hardware-Software Stack for Deep Learningの翻訳と簡単な感想を書きました(^o^)
TVM開発チームには許可を頂いていますが、もし誤訳があったら教えてください。原文は以下です。
https://arxiv.org/abs/1807.04188
1. VTAとは
Versatile Tensor Acceleratorの略。
汎用的かつ高速、効率的なHW Deep learningアクセラレータを提供するスタックの総称。
提供されるアクセラレータはプログラム可能であり、柔軟にカスタマイズができる。
VTAは生産性重視で高レベル記述が可能なDLフレームワークと性能重視で低レベルな基盤ハードウェア(FPGAなど)におけるブリッジになることを目的としている。
そのため、アクセラレータ以外にもドライバやJitランタイム、TVMに基づいた最適化済みコンパイラ環境も提供しており、End-to-Endで動作する。
また、FPGAにデプロイするためのインターフェイスや振る舞いHWシュミレーション機能も含まれている。
どのような人や用途に有効なのか
- HWデザイナとコンピュータアーキテクト
- 最適化コンパイラのリサーチャ
- Deep learningのリサーチャ
全体構成
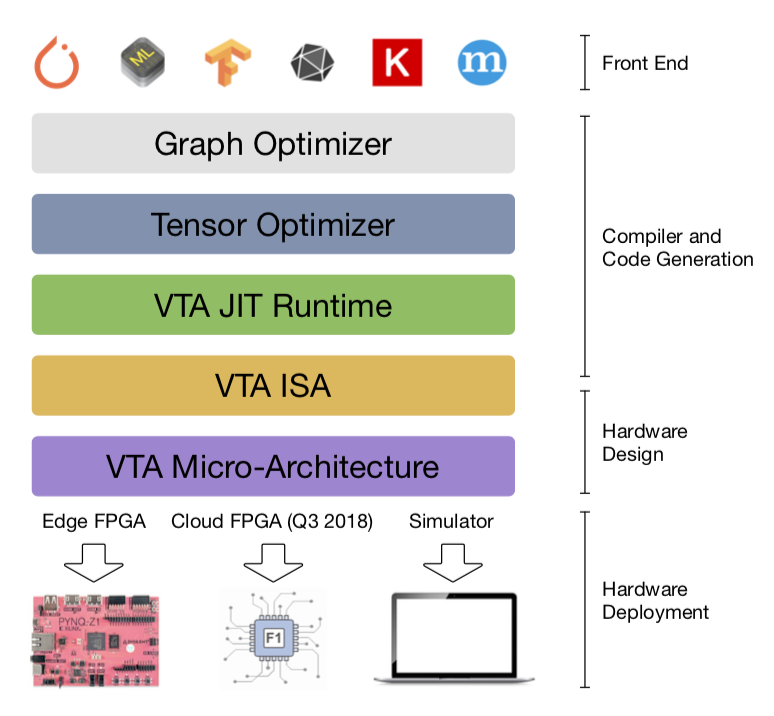
- NNVM Intermediate Representation
- TVM Intermediate Representation
- VTA JIT Runtime
- VTA Instruction Set Architecture
- VTA Hardware Micro-Architecture
2. VTA Hardware Architecture
VTAは他の主要なDLアクセラレータと同様に、密線形代数演算を高速に実行できるように設計されている。(Google TPU等から着想を得ている)
また、RISCに似たISAを採用し、ランク1, 2の行列演算をサポートする。
アクセス、実行分離の手法を採用することでメモリのレイテンシを隠蔽できるように設計されている。
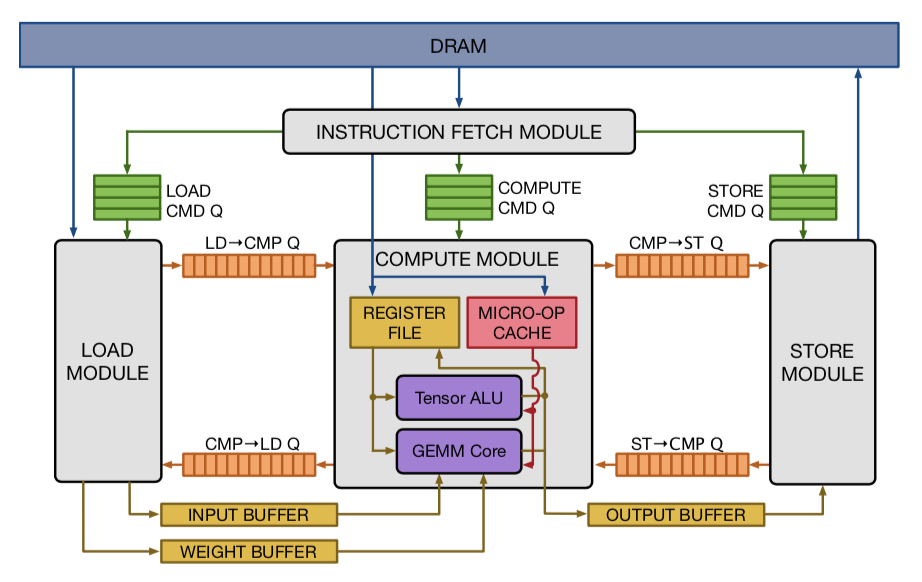
2.1 VTA Design Overview
VTAは4つのモジュールを含んでおり、これらはFIFOキューもしくはローカルメモリブロックを介して互いに連携する事ができる。これはタスクレベルのパイプライン並列化を可能にする。
モジュールの説明
-
fetch module
命令ストリームをDRAMから読み込み、それらをデコードして下3つ命令のどれかに転送する。 -
load module
入力と重みの行列データをDRAMからロードし、そのデータ専用のオンチップメモリに保存する。 -
compute module
密線形代数演算はGEMM coreを用いて、一般演算はtensor ALUを用いて計算する。また、DRAMからデータをレジスタファイルに、マイクロOPカーネルをキャッシュにそれぞれロードする。
@演算のレイテンシが違うので、どのようにスケジューリングするか気になる -
store module
compute moduleの計算結果をDRAMに書き戻す。
2.2 VTA ISA
ISAは4つのCISC命令からなり、これらは可変な実行レイテンシを持つ。それらのうち2つはマイクロコードされた命令シーケンスを実行する。これらのCISC命令はTPUやCambriconの命令セットに非常に類似している。そのため、VTAは公に公開されていないハードウェアデザインを対象としたコンパイラ最適化の実験としても用いることができる。
-
LOAD instruction
DRAMから2Dのテンソルを入力バッファまたはレジスタファイルに読み込む。また同様に、マイクロカーネルをマイクロOPキャッシュに読み込む。タイル化された入力と重みが読み込まれる場合には動的パディングがサポートされる。 -
STORE instruction
出力バッファからをDRAMへ2Dテンソルを書き戻す。

-
GEMM instruction
入力テンソルと重みテンソルに対して、行列-行列積のマイクロOPシーケンスを実行し、結果をレジスタファイル内のテンソルに加算する。

-
ALU instruction
レジスタファイル内のテンソルデータに対して、行列-行列 ALU演算のマイクロOPシーケンスを実行する。

Load命令はストアメモリバッファの位置によってloadとcomputeモジュールにより実行される。GEMMと ALU命令はcomputeモジュールのGEMMコアとテンソルALUにより実行される。最後にSTORE命令がstoreモジュールによって排他的に実行される。
VTAはそのアーキテクチャのパラメータを変更することが可能であり(例: GEMMMコアの形状やデータ型、メモリサイズなど)、これは結果として、ISAがすべてのVTAの変更に対して互換性を保証することはできない。しかし、これらはVTA runtimeがそのパラメータの変更と特定の設定で生成されたアクセラレータで動作するバイナリプログラムに適用することで許容できる。これはHW-SW間のインターフェイスの流動性を取り入れるために、VTAスタックで採用されたの協調設計哲学の一つらしい。
2.3 Task-Level Pipeline Parallelism
計算資源を常にbusyに保つためにメモリマネジメントを正しく行うことが、効率的なHW設計を行うための重要な点であり、Task-Level Pipeline Parallelism (TLPP)はその中でも特に重要で良く知られている手法だ。 これにより計算機とメモリの資源を同時に使用することで資源の利用率を最大化することができる。TLPPはGoogle TPUでも用いられているaccess-execute分離の技術を用いて実現されている。
現代のHW設計において当たり前の技術だけど、きちんとした定義や研究がなされていたことは知らなかった^^;
基礎概念にたち戻ってきちんと勉強する時間を設けたいなー
Latency Hiding
以下の図は、TLPPにおけるaccess-execute分離による効率性を示している。
複数の命令が同時に別々のHWモジュールを実行することで、メモリ演算と計算演算を並列に実行することができる。
図5
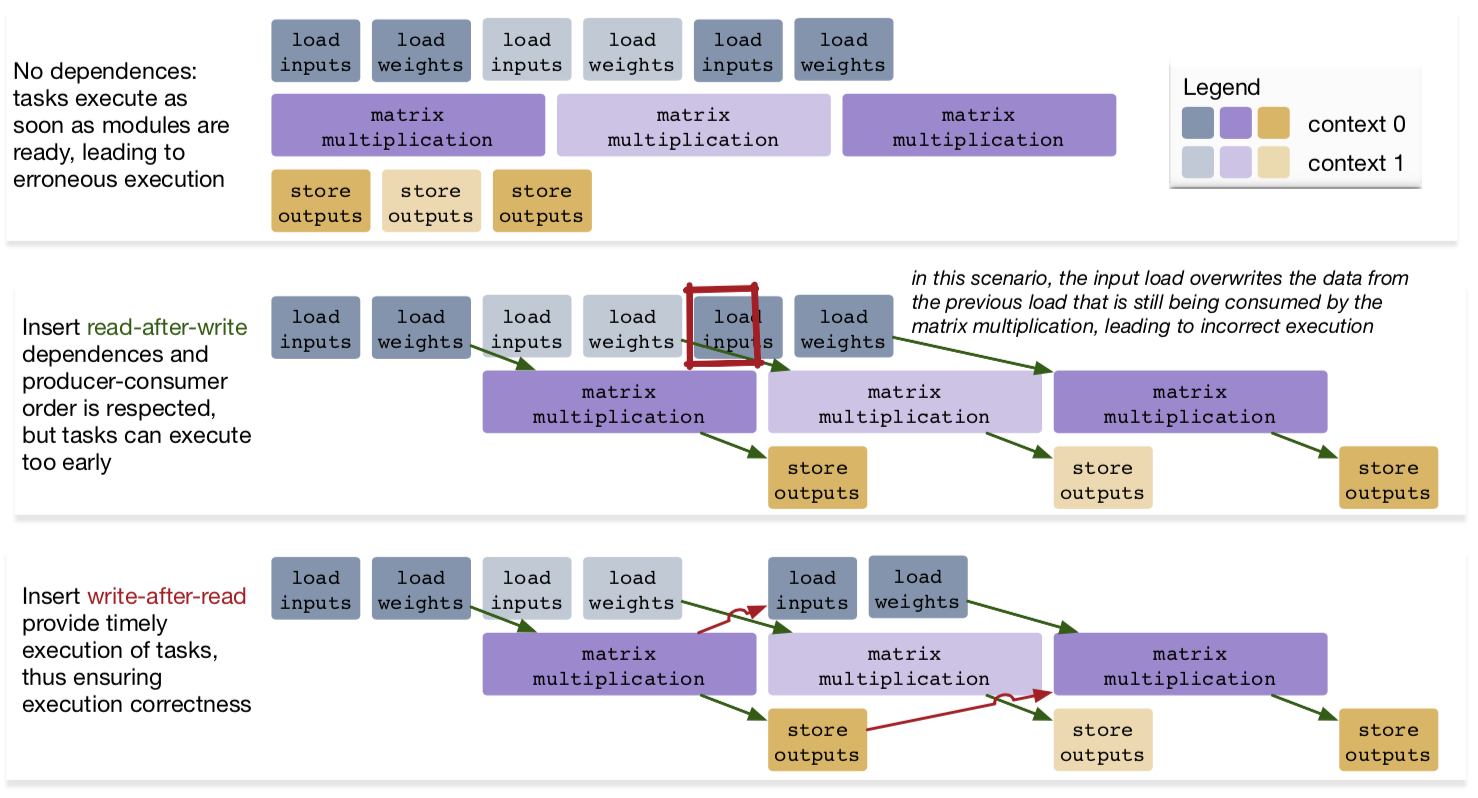
Data Dependences
メモリアクセスと実行を分離するHWを実装するには、命令館において明示的にデータの依存関係を指定する必要がある。ここでメモリは入力と出力の2つに排他的に分離されているとして、3種類のデータ依存関係に対してその正しさと効率性を比較してみる。
-
No dependency:
すべての命令はそれぞれのHWモジュールが利用可能になり次第実行され、可能な限り早く終了する。しかし、これでは計算が終わる前に出力がなされ誤った実行となってしまう。 -
read-after-write:
最初の計算および出力は正しく実行される。しかし、2つ目のロードが終了した直後に3つ目のロードが即座に始まってしまい、バッファ内の2つ目のデータは上書きされてしまう。よって2つ目の演算の結果が誤りとなる。。 -
write-after-read:
出力と同時に次の次のデータのロードを開始することで、常にデータの整合性が保たれる。
シーケンシャルデータに対する演算をHWで実装する際に良く知られている方法だが、単純な実装だとアクセスと演算におけるレイテンシ差が大きいと非効率になる。演算レイテンシが大きい場合は内部のバッファを増やして投機的にデータをロード、もしくは演算器を並列化して複数命令間において分配して利用するという手法が考えられるけど、アクセスが遅い時はやはりボトルネックになってしまうのかな?(゜-゜)
Dataflow Execution
次にVTAがどのように物理的に上記にの依存性を付加しているかを見ていく。
VTAは同時タスク実行の同期するために、HWモジュール間に配置したdependence FIFOキューを用いている。これはデータフローモデルにおけるproducer-consumer手法だと言える。
ISAの図にあるように、すべての命令はDependence flagsを持っている。これらはHW内でデコードされ、モジュールが命令を実行する際にそのの動作を制御する。正確に言うと、モジュールは与えられた命令に含まれる他の命令と依存関係を考慮した上で、それをどのように実行するかを決定するということだろう。
図6
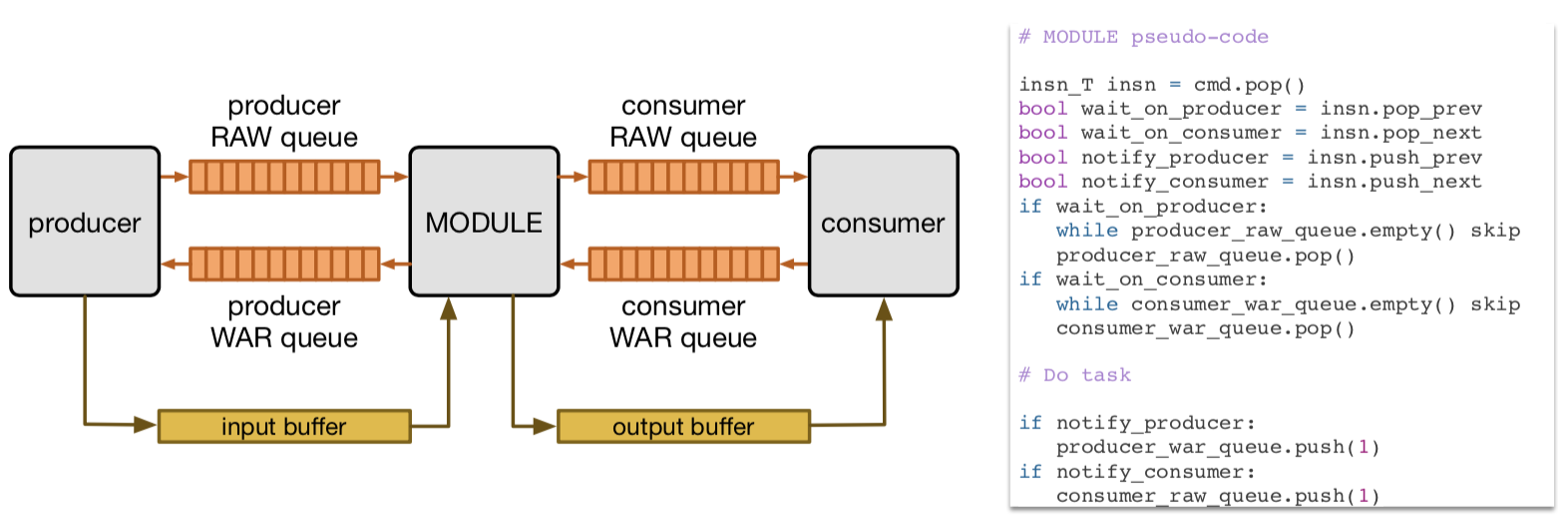
上にどのようにしてモジュール間が接続されているかを示した図とその実行例を記述した擬似コードがある。
Pipeline Expandibility
図5でVTAデザインが、3ステージのタスクパイプライン(load, compute, store)を記述する4つのモジュールから構成されることを示した。VTAハードウェアの構成原理は、図6にあるように「デザイン内部の各のモジュールがそれ自身のプロデューサとコンシューマとdependence FIFOキューと単一read/単一writeのSRAMを介して接続されていること」にあるらしい。
ただ、上記以外でもパイプラインに新たなステージを追加することが可能だ。例えば、GEMMの利用効率を最大化するために、テンソルALUとGEMMコアを分離することを考えると、タスクパイプラインはおそらくload-gemm-activate-storeとなる。これは更にTPUに近い発想だと言えるだろう。しかし、新たなステージを追加することはストレージと余分なロジックオーバヘッドコストを必要とするため、標準では3ステージのパイプラインを選択したようだ。
2.4 Instruction Decoding with the fetch Module
どのようにしてfetchモジュールによって命令がデコードされるのかを見ていく。
まず、VTAは線形演算命令列によりプログラムされ、これらの命令はCISCに似たマルチサイクル命令によって記述される。
これらはLOAD, GEMM, ALU, STOREの4つの命令タイプに分割される。
fetchモジュールはVTAにおけるCPUへのエントリポイントであり、3つのメモリマップのレジスタを介してプログラムされる。
-
control レジスタ
読み書き可能 であり、fetchモジュールの開始と終了の確認に利用される。 -
insn_count レジスタ
書き込みのみ可能であり、実行する命令列の長さを格納する。 -
insns レジスタ
DRAM内の命令列の開始アドレスを格納する。
fetchモジュールの動作手順は以下のようになる
- CPU: VTAランタイムが実行したい命令列をDRAM上の物理的に連続した領域として確保する
- CPU: insn レジスタに開始アドレス、insn_countレジスタに命令列の長さを格納する。
- CPU: constrollレジスタのスタート信号を有効化
- VTA: 命令をDRAMからDMAを介して取得する。
fetchモジュールが命令列にアクセスした時、命令を部分的にデコードして命令キユーにプッシュする。
命令キューは上記をload,compute,storeモジュールのどれかに以下のようにフィードする。
- STORE命令はstore命令キューにプッシュされる。
- GEMM とALU命令はcompute命令キューにプッシュする。
- micro-opカーネルまたはレジスタファイルに対するロード命令の記述するLOAD命令は。LOAD命令は計算命令キューにプッシュされる。
- 入力もしくは重みデータに対するロード命令はロード命令キューにプッシュされる。
命令キューが満タンになるとfetchモジュールはキューが空くまでストールされる。
広い実行ウィンドウを可能にしたり、load-compute-storeパイプラインの上で複数タスクを同時に実行できるようにするために、命令キューはその深さが十分になるように調整されるらしい。
2.5 VTA Compute Core
VTAのcomputeコアはRISCプロセッサのように振る舞い、スカラレジスタよりむしろテンソルレジスタ上での計算を実行する。
テンソルレジスタ上での計算において、ALUとGEMM2つの機能的な計算ユニットがある。
ALUは要素ごとの加算など演算強度の低いテンソル演算を実行する。一方でGEMMコアは、行列積など演算強度の高い演算を入力、重みバッファのデータに対して実行する。
演算結果はレジスタファイルに書き込まれ、同時に出力バッファにも書き込まれてDRAMへと格納される。
Micro-Ops
computeコアはRISCに似たmicro-ops をmicro-opキャッシュから取り出し実行する。micro-opは上述したALUとGEMMによってそれぞれ異なる。
micro-opカーネルは、そのフットプリントを最小化するために条件付きジャンプ命令などのフロー制御命令を含まなず、を2つのネストしたループによって定められるレジスタの位置に対して、連続した命令列を実行する。
この際、GEMMコアは行列積とConv2Dに使い回されるようだ。
GEMM Core
2つのネストしたループ内のマイクロコードシーケンスを実行することで、GEMM命令を実装している。
GEMMコアは入力-重み行列積を単一サイクルで実行できる。
単一サイクル行列積の次元はハードウェアのtensorization intrinsicに定義される。そのためにはTVMコンパイラが計算スケジュールをロアーリングしなければならない。このtensorization intrinsicは入力と重み、アキュミュレータレジスタの次元から定義される。また、各データ型は低精度を用いており、入力と重みは8bits以下、アキュミュレータは32bitである。
Tensor ALU
Tensor ALUではよく使われる計算や活性、正規化、プーリング演算がサポートされている。
Found
ビット幅
input 8bit (3)
weight 8bit (3)
accumulation 32bit (32)
>> python tvm/vta/config/vta_config.py --get-inpwidth
3
>> tvm/vta/config/vta_config.py --get-wgtwidth
3
>> tvm/vta/config/vta_config.py --get-accwidth
5
出力ビット幅の制約
VTAは低ビットのenv.inp_dtypeデータ型のDRAMストアのみをサポートしている。
これにより、メモリ転送のデータフットプリントを削減できたり、広いビット幅のアキュムレータのデータ型を入力アクティベーションデータ型に一致するデータ形式に量子化することもできる。
これはニューラルネットワーク推論において、活性化後の出力が、次の層によって直接消費されることが多いためである。
レジスタファイル
ACCレジスタファイルはVTAのgeneral purpose registerとして利用される。
これは行列積やコンボリューション、プーリング、バッチノーマリゼーションの一時結果を保存するためにも利用される。
>> tvm/vta/config/vta_config.py --get-accbuffsize
17
>> tvm/vta/config/vta_config.py --get-inpbuffsize
15
>> tvm/vta/config/vta_config.py --get-wgtbuffsize
18
2.6 VTA Memory System
VTAは各データに専用のSRAMで構成された、単一レベルのメモリ改装を持っている。
これらはコンフィグレーションされたビット幅によりサイズが決定する。(例: BATCH=2, BLOCK_IN=16, and BLOCK_OUT=16)
各SRAMは各HWモジュールに対して単方向のreader/writerに接続されており、同時に実行できるようになっている。
メモリ帯域への考慮
各データの種類に特化したブッファを用意することで、GEMMコアをビジーに保つためにそれぞれのSRAMに適切な帯域幅を設定できる。
例えば、8bitの重みと32bitのアキュミュレータ, BATCH=2, BLOCK_IN=16, BLOCK_OUT=16 の場合、
200MHzの周波数下においてGEMMコアをbusyに保つための各入力バッファにおけるメモリ帯域は51.2Gb/s, 409.6Gb/s, 204.8Gb/sとなる。
これらの相違が理由で、VTAは単一バッファではなく、複数の異なるサイズを持つバッファを用意しているようだ。
メモリレイテンシの隠蔽
VTAのloadモジュールは、DRAMからデータをを入力と重みSRAMに、storeモジュールは出力SRAMからDRAMにデータをそれぞれDMA 転送する。
これらの実行は計算がcomputeコア内で実行されている間に行なわれ、latency-hidingのメカニズムと呼ばれる。
タイルアクセスパターン
load とstoreモジュールはDRAMに対して、 二次元にストライドされた 読み書きを実行する。
この特徴は単一転送において読み書きを記述する際に有用であり。これは以下の図のようload モジュールは動的にパディングを挿入することで、2次元コンボリューションの際にパッキングのオーバーヘッド無しで入力を重みのテンソルをタイル化できるということらしい。

3. VTA ランタイムシステム
VTAのランタイムライブラリは ロアーリングされた TVMスケジュールが呼び出すことができるハードウェア命令のC++APIを提供する。
アクセラレータのバイナリにおいてJITコンパイルを実行し、同期にメモリ割り当てを行い、アクセラレータと同期をとることで、TVMコンパイラとVTAのローレベルプログラミングインターフェイスを繋ぐ役割をになる事ができる。
3.1 コンパイルの概観
ランタイムの役割はTVMコンパイルフローの中で説明することができ、ARMベースのSoCをターゲットにした例が下図に示されている。

ターゲットとなるARM 組み込みシステムはTVM RPCサーバを起動、JITランタイムライブラリを読み込み、その後に来るリクエストを読み続ける。コンパイルされたTVMカーネルオブジェクトを受信すると、RPCサーバはこれをTVMモジュールにロードし、そのハンドルをホストに返す。このモジュールハンドルは最終的にホストから遠隔に起動され、JITコンパイルの開始、メモリの割当て、TVMカーネルをVTAにオフロードするためのCPUとVTA間の同期タスクを行う。
3.2 JIT ランタイム
VIAのJITランタイムは計算をVTAにオフロードするために必要な簿記タスクを行う。これは次のように動作するC++のAPIとして提供される。
- 動的メモリ割り当てとバッファ管理
- メインメモリ(DRAM)とアクセラレータのメモリ(SRAM)間におけるDMA転送
- マイクロカーネルの生成とキャッシュ
- 命令ストリームにおける明示的な依存の管理
- ターゲットCPUとVTA間での同期
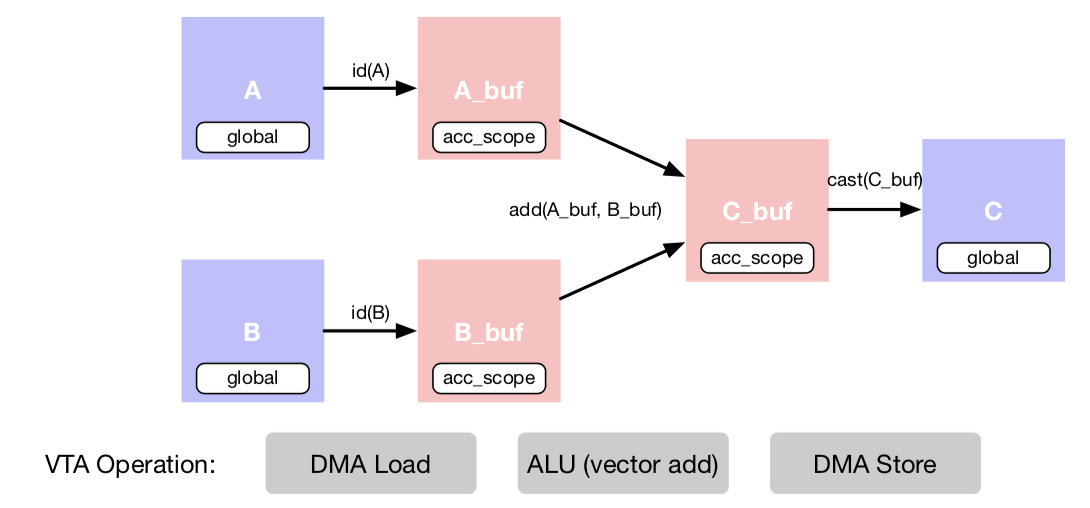
これらランタイム機能のそれぞれについて、上記のグラフ内にあるベクトル加算の実行を行う例を用いて説明を行う。
TVMスケジュールは上記のスケジュール最適化の結果をロアーリングしたものであり、内部でVTAランタイムを呼び出すことがわかる。
// attr [A_buf] storage_scope = "local . acc_buffer"
// attr [iter_var(vta , , vta)] coproc_scope = 2
produce A_buf {
VTALoadBuffer2D(tvm_thread_context(VTATLSCommandHandle()), A, 0, 64, 1, 64, 0, 0, 0, 0, 0, 3)
}
produce B_buf {
VTALoadBuffer2D(tvm_thread_context(VTATLSCommandHandle()), B, 0, 64, 1, 64, 0, 0, 0, 0, 64, 3)
}
// attr [iter_var(vta , , vta)] coproc_uop_scope = "VTAPushALUOp"
produce C_buf {
VTAUopLoopBegin(64, 1, 1, 0)
VTAUopPush(1, 0, 0, 64, 0, 2, 0, 0)
VTAUopLoopEnd ( )
}
vta.coproc_dep_push (2 , 3)
// attr [iter_var(vta , , vta)] coproc_scope = 3
vta.coproc_dep_pop (2 , 3)
produce C {
VTAStoreBuffer2D(tvm_thread_context(VTATLSCommandHandle()), 0, 4, C, 0, 64, 1, 64)
}
vta.coproc_sync ()
Cバッファにデータを戻す際はCastが起こって8bit戻ってしまいそうだけど、アクティベーション なしではメインメモリに書き直せなさそう。後、アクティベーションがシグモイドみたいな やつだとどうなるんだろうか。 固定小数点を使うのかな?(゜゜)
動的メモリ割り当て
VTAランタイムメモリアロケータはAPIはVTABufferAlloc()とVTABufferCopy()を含み、物理的に連続なメモリ領域をDRAM内に確保または開放する。バッファを割り当てる際に、ランタイムはアクセラレータへの物理アドレスを提供する。
CPUとVTAがコヒーレンシの取れたメモリアクセスを共有するというシナリオにおいて、キャッシュのフラッシュやバリデーションの解除を実行する必要はない。反対に、ランタイムはCPU がバッファを読む前にキャッシュのバリデーション解除を行い、CPUがバッファに書き終えた後にキャッシュをフラッシュする。
DMA転送
DMA転送は巨大なサイズのメモリをDRAMとアクセラレータ上のSRAM感に確保することを可能にする。これらはVTAモジュール内のDMAマスターにより、FPGAメモリコントローラを通して初期化される。
VTAは2次元にストライドされたアクセスパターンをサポートしており、これはテンソルのサイズがVTAのオンチップSRAMにフィットしない場合にタイリングを行う。
Micro-Opカーネル生成
LOADとSTORE、ALU、GEMMから構成される命令ストリームの生成に加えて、VTA Runtimeはmicro-opカーネルの生成と管理を行う。micro-opカーネルは計算タスクのアクセスパターンを記述するために、各単一の計算命令それぞれに対して生成される必要がある。例えば、ウィンドウサイズが3でストライドが1の2Dコンボリューションはウィンドウサイズが7、ストライドが2のコンボリューションとは異なるアクセスパタンを持つだろう。
明示的依存の管理
上のベクタ加算の例に示されるように、この実行時におけるmicro-opカーネル生成はVTAUopLoopBegin()とVTAUopLoopEnd、VTAUopPush()ランタイムAPI関数によって制御される。BeginとEnd関数はmicro-kernelを用意、梱包してCSIC命令を生成する。これらは後にkernelを呼び出す。各micro-kernelは生成された後、プログラムのライフタイム全体に渡ってDRAM内にキャッシュされる。*VTAUopPush()*がコールされた時、ランタイムはVTA micro-opを現在のmicro-kernelに追加し、カーネルを構築する。ランタイムは、VTAのmicro-opキャッシュと各micro-kernelをいつ取り替えるかを決定する。その際の選択はLRUキャッシュ取替の方策を用いて行う。
明示的な依存の制御
前章でタスクレベルのパイプラインを実現する上で必要な命令ストリーム内における依存をラベリングすることを述べた。
下図で示されるように、ランタイムは上記の依存を明示的に挿入するAPIを提供する。VTADepPop()やVTADepPush()は現在実行中の命令の依存フラグのセットを呼び出し、2つの命令感における依存を挿入する。
ここではLOAD命令とそれに引き続くADD命令に対して、どのようにランタイムがRAW依存を強制するかを見ていく。
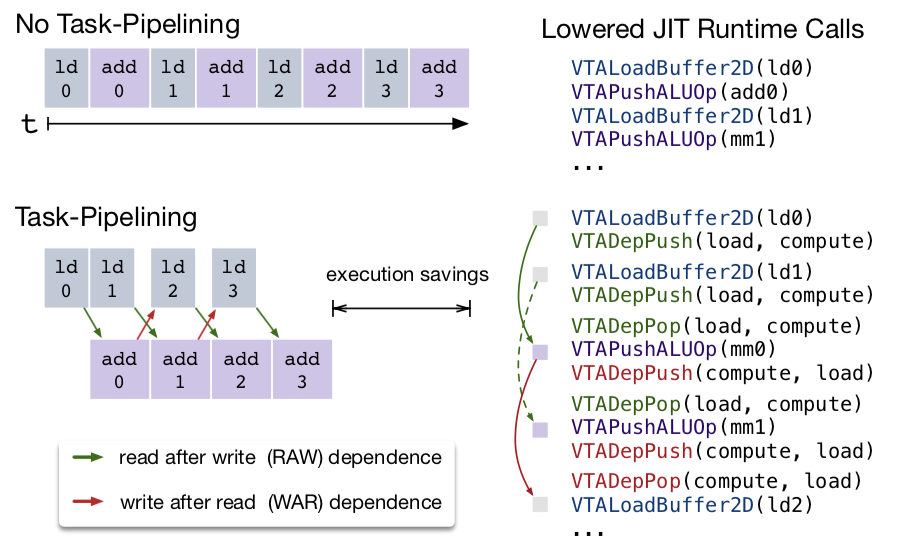
初めに、ld0命令が用意される間にVTADepPush(load, compute)が呼ばれる。これはld0命令の依存フラグをセットするので、その命令がloadモジュールで実行されるときに依存トークンはcomputeハードウェアモジュールにつながるRAW依存FIFOにプッシュされる。次に、VTADepPop(load, compute)がadd0命令の前に呼ばれ る。これは次に来るadd0命令の依存フラグをセットする。add0 命令がcomputeモジュールによって計算されたときに、2つの命令間の依存を強制するために、前にld0がRAW依存FIFOにプッシュした依存トークンをポップする。
CPU-VTA間の同期
VTAのランタイムは協調的なオフロード作業を行うために、CPUとアクセラレータ間の同期を行う。これはVTASynchronize()ランタイムより可能になり、命令ストリームやマイクロカーネルの準備、アクセラータのスタンドアロンな制御を提供する。VTAは命令ストリームをフェッチした後、DRAMからの入力と出力DMAを初期化する。その後、ランタイムはアクセラレータがその計算が終わったことを告知するのを待つ。
4 VTAへのTVMのサポート
TVMは公開されたIRとより複数のHWバックエンド上で効率の良いコードを提供するためのスケジューリングセット、実行環境に依存しないアルゴリズム記述機能を持った最適化コンパイラスタックである。有効な複数の実行プロセスを生成するという手法はHalideのアイディアに基づいている。
以下の図はTVMのスケジュール変換をハードウェアに依存しない高次元な行列席の式を、VTAを対象としたを低レベルな実装にどのように変換するのかを示したものである。このアイディアはスケジューリングにより基本的な変形のセットをオリジナルプログラムに作用させ、論理的な等価性を保ったまま徐々に変換していくというものである。変換後はVTAに対してロアーリングされたスケジュールはVTAランタイムを直接実行し、アクセラレータ用のバイナリをその場で変換する。

引き続くセクションで、VTA向けのスケジュール変換を適用するのにTVMがどのように利用されているのかを示す。TVMを作成した直後は、低レベルな実装を完全に公開した商用的なDNNアクセラレータは存在しなかった、従ってVTAはTVMが提供するアクセラレータに特化したスケジューリング最適化のセットの開発に役立つ、良い例になるだろう。
以下で、明示的なメモリ管理、テンソル化、レイテンシ隠蔽といったVTAのような深い学習アクセラレータを対象とした課題に取り組む3つのスケジューリングプリミティブについて説明する。
4.1 明示的なメモリ制御
DNNアクセラレータが通常のCPUやGPUと異なる観点の一つは明示的なオンチップメモリの管理である。CPUでは、キャッシュが暗黙に最も直近にアクセスされたデータを保持している。一方でTPUのようなアクセラレータに対しては、コンパイラがデータが入力、もしくは出力される必要があるかを明示的に指定しなければならない。
TVMはmemory scopeの概念をスケジュール空間に提供し、compute ステージのバッファは明示的なメモリ領域(AL, BL, CL)に割当られる。VTAのプログラミングコンセプトにおいて、メモリスコープはTVMバッファを特定のメモリ領域に割り当てることを可能にし、その領域専用のロアーリングルールを作成する。
4.2 Tensorization
DNNアクセラレータは、行列-行列積または行列-ベクトル積に計算に特化したハードウェア機能ユニットとディープラーニングの高い演算強度(演算とメモリアクセスの比)を利用する。この増大傾向に対処するため、TVMは高い演算強度のテンソルのハードウェア組み込み命令を密な計算をマッピングするためのtensorizationスケジューリングプリミティブを導入した。TensorizationはSIMDアーキテクチャにおけるベクトル化に類似しており、与えられスケジュールをシングルサイクルの行列積や1Dコンボリューションのようなテンソルハードウェア組込み命令に自動的に分解するように試みる。しかし、テンソルの高次元化のため、テンソルはデータレイアウト制約を満たすようにループを変更し、計算グラフ全体をテンソルハードウェア組み込み関数にマッピングする必要がある。
上記の図は行列積CLを計算するプロセスにおけるスケジュールに対して、tensorizationがどのように適用されるのかを示している。上記の(8 x 8)行列-行列積をVTAのGEMMコア組み込み命令にロアーリングしている例である。Tensorizationの適用に必要な前処理として、ループをテンソル組み込み命令に合うようにタイル化する必要がある。
4.3 明示的なメモリレイテンシの隠蔽
VTAはランタイムのレイテンシを減らすため、アクセスと実行の命令パイプラインを分離している。上の明示的な依存挿入の例で議論したとおり、明示的な低レベルの動機を必要とするアクセラレータを用いたプログラミングは困難である。このようなプログラマーの負担を軽減するため、TVMはvirtual threadingというスケジュールプリミティブを提供する。これはプログラマがマルチスレッドCPUのプログラミングを行うのと同じ方法で、高レベルデータパラレルプログラムを指定することを可能にする。
TVMは自動的に論理スレッド化されたプログラムを、下図で示されるような単一の命令ストリームと低レベルな明示的同期にロアーリングする。
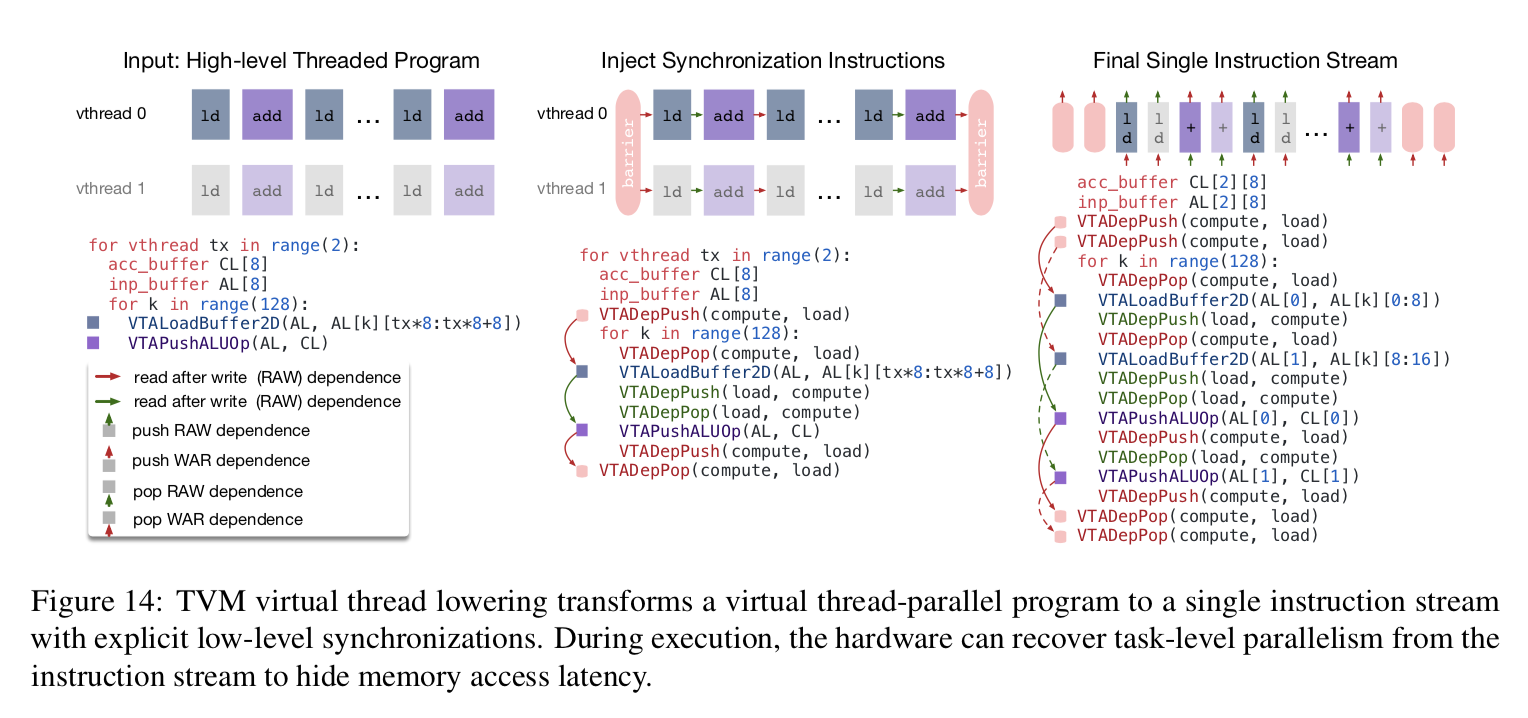
このアルゴリズムは高レベルのマルチスレッド化されたプログラム・スケジュールとともに始まり、各スレッド内部で正しい実行を保証するために必要な低レベル同期演算を挿入する。次に、全ての仮想スレッドの演算を単一の命令ストリームに織り交ぜ、最終的にハードウェアは命令ストリーム内の低レベル同期によって指示された利用可能なパイプラインの並列性を利用する。
5. 評価
この章では低コストのPYNQ FPGAボード上でVTAの評価を行う。FPGA開発ボードは1MB以下のオンチップストレージを搭載した2012SoCである。この開発ボードはアカデミックであっても手入手しやすく、かつ限定的な資源におけるハードウェアデザインに挑戦したいという理由で選択した。評価のポイントは対象としたハードウェア上で達成されたピーク性能より、フルスタックで動作するという点に着目した。性能の観点ではまだまだ多く改善の余地がある。我々はオープンソースコミュニティの助けを借りてハードウェアとソフトウェアのスタックを繰り返し適用することで、このプラットフォームとFPGAの今後の業績に到達することを目指している。
プラットフォーム
VTAをPYNQボード(CPU: ARM Cortex A9, 667MHz & FPGA Fabric)を用いて実装を行った。
ここでは100MHzで動作する16 x 16行列積ユニットを実装し、これは8-bitの乗算と32bitのアキュミュレータを持つ。この場合、理論的ピークスループットは51GOPS/sである。我々は16kBのマイクロカーネルチャッシュ32kBのアクティベーションストレージを256kBのパラメータストレージと128kBのレジスタファイル(アキュミュレータ)を割り当てた。これらのオンチップバッファはResNetの単一の層に十分なオンチップストレージを提供するほどには大きくないため、効果的なメモリ再利用とメモリアクセスレイテンシの隠蔽のための動機付けのケーススタディを提供します。
ベンチマーク
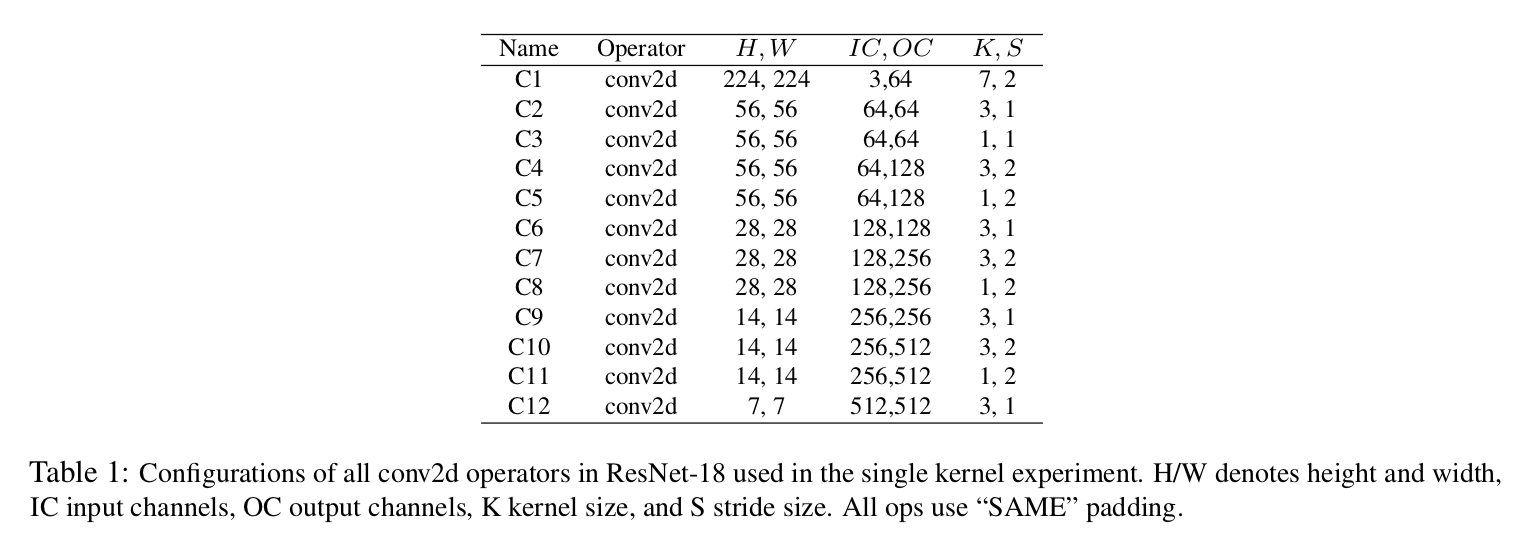
ベンチマークにはMxNetを用いてトレーニングされたResNet-18を用いる。これは32-bit floatの重みパラメータを8-bitに事前に変換されており、変換後の精度はImageNetにおけるトップ5において63%である。実行では、初めのレイヤを除く(入力チャネル数が少ないため)全てのコンボリューションレイヤをFPGAアクセラレータにオフロードする。また、マックスプーリングと全結合層はCPUで評価する。以下の表に使用したResnet-18の全層のパラメータをまとめておく。
計算資源の効率性
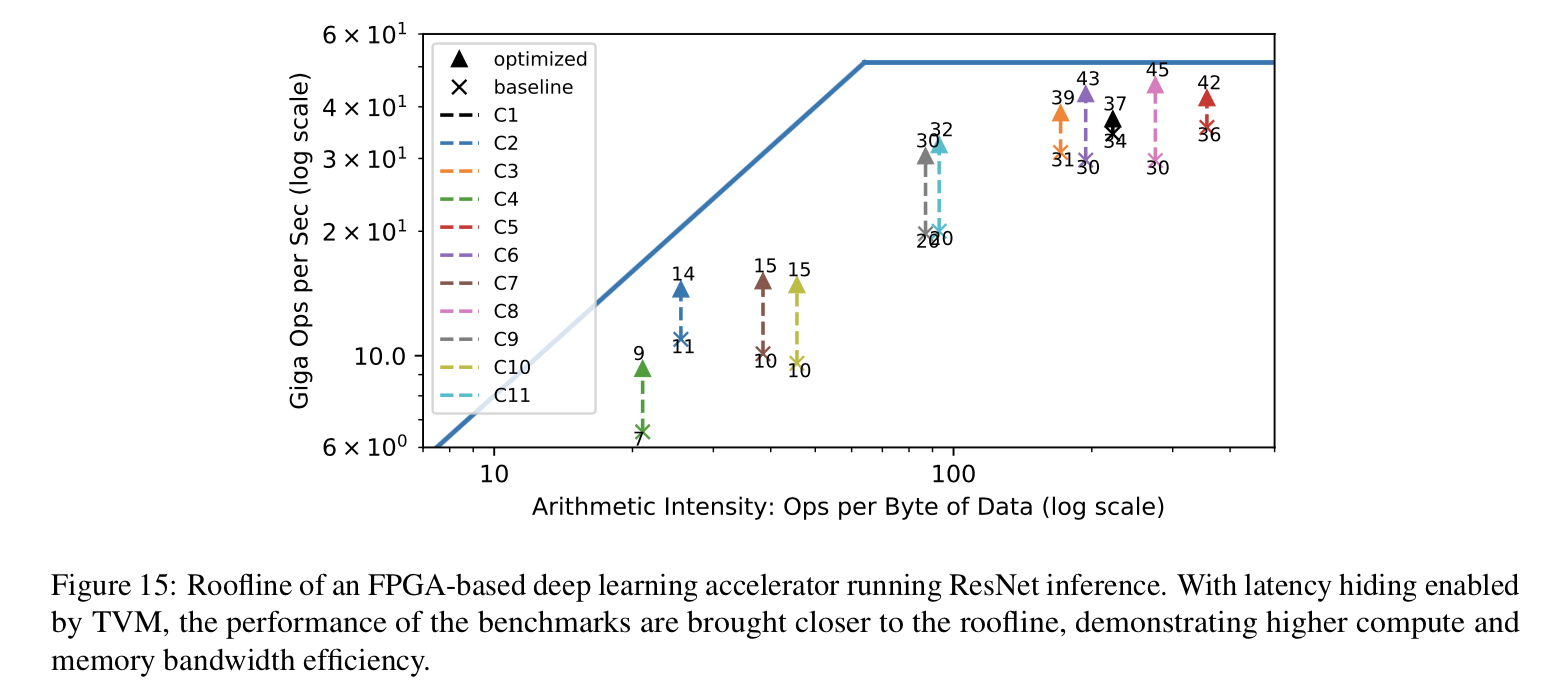
ルーフラインダイアグラムはハードウェアの利用率の効率性を確認するためによく使われる手法である。以下の図はResNet-18の異なるコンボリューション層において計測された推論ベンチマークのスループットを示している。各層は異なる演算強度(すなわち計算とデータ移動の比)を持つ。左半分の領域にあるコンボリューション層は帯域に制限されており、右半分にある方は演算が制限となる。
HWアーキテクチャをそのコンパイラスタックと共に設計することの目的は各ワークロードを可能な限りループラインに近づけることを可能にするためである。プロットは使用可能なハードウェアリソースの使用率を最大限に引き出すために、ハードウェアとコンパイラを強調動作させた結果を示している。ここではレイテンシの隠蔽技術が利用されており、これは明示的な依存をハードウェアのレベルでトラッキングや仮想スレッドを通じた動作のパーティションを目的としたコンパイラサポート、及びJITコード生成時に作られる命令ストリームに明示的な依存を挿入することを必要とする。その結果、利用可能な計算およびメモリ資源において全体的に高い利用率が得られた。仮想スレッドを有効にすることによってピーク時の計算ユニットの利用率は70%から88%に向上する。この実験では、VTA-TVMスタックのハードウェア層とコンパイラ層の両方に可視性が必要なクロススタック最適化の実装に対しての可能性が示されている。
End to End Resnet Evaluation
本論文ではTVMを用いてResNetの推論用カーネルをPYNQプラットフォーム上に生成し、可能なり多くの層をVTAにオフロードした。TVMを活用し、CPUとCPU+FPGAの両方の実装に対してスケジュールを生成した。初めのコンボリューション層は、入力チャンネルが小さいため、CPU上で実行した。他のコンボリューション層は問題なくオフロードできた。レジデュアル層とマックスプーリングは共にCPU上で実装されている。これはTVMがそれらの演算をサポートしていないためである。
VTAに対して完全なコンパイラスタックを持つことの利点はEnd-to-Endで動作するワークロードが可能になる点である。
ハードウェアアクセラレーションのコンテキストにおいて、この手法は魅力的である。なぜなら、より高速なパフォーマンスを得るため、この手法を通してパフォーマンスのボトルネックやアムダールの制限が有効であるかを理解できるためである。下図ではPYNQボード上でコンボリューションをFPGA-baseのVTAデザインにオフロードした場合としなかった場合の推論性能を示している。一見しただけでもVTAはコンボリューションに必要な時間を削減するだけで、全体の推論時間を3秒から0.5秒まで高速化している。しかし、推論の待ち時間をさらに短縮したい場合、他のオペレータがオフロードを必要とすることは明らかである。この種の可視化性はマイクロカーネルの背後にある完全な挙動を理解したいシステムの設計者には必須である。
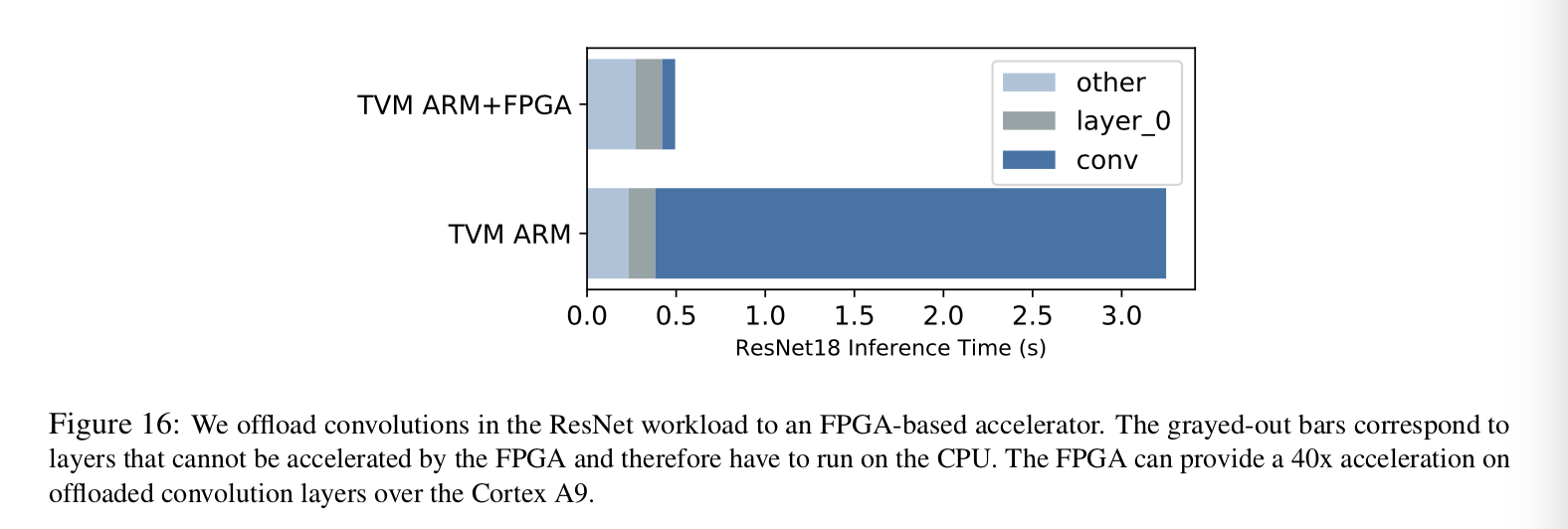
Restnet-18はRaspberry Pi3を使うと0.3sくらいで実行できるからこれでもまだ負けているな ーと思っていたけど、なるほどコンボリューションに以外の層はオフロードしていないのね。納得。(゜-゜)
一度、自分のPYNQのCPUのみで実行してみたいなー。
6. 結論
本論文では多目的なテンソルアクセラレータ(VTA)を提案した。これはオープンかつ包括的で、カスタマイズが可能なディープラーニングアクセラレータであり、クロススタックなディープラーニングのリサーチや最適化に役に立つであろう。VTAはTVMベースのコンパイラスタックとJITランタイムである。このフルスタックな構成は、End-to-Endのワークロードにおいて、高レベルのディープラーニングフレームワークからそのままVTAを利用することを可能にする。また、ここでは低コストのPYNQ FPGA評価環境でその評価を行い、VTAとTVMスタックが完全に強調して動作することを示した。
VTAはGithub上のTVMリポジトリでメインラインにマージされており、誰でも利用可能である。
やはり、TVMを用いてEnd-to-Endで動くのはものすごく便利。
まだまだ性能は 向上すると言っている通り、Github上の情報ではintelHLSに対応したり、上記で500msだったのが今は200ms 台で動くという情報も上がっているので、今後に期待大です。 (^o^)
https://github.com/dmlc/tvm/issues/1656
コメント
コメントを投稿